Ray技术入门-编译部署和任务生命周期
背景知识
Ray是一个使用Bazel构建的,基于gRPC上层打造的开源分布式计算框架,旨在简化分布式应用的开发和运行。它支持无缝地将 Python 代码扩展到多核、多节点环境,适合构建高性能的分布式系统。Ray 提供灵活的任务调度和状态管理,支持多种编程模型,包括任务并行和 actor 模式,并通过自动化的资源管理和容错机制简化复杂分布式工作的部署。它还拥有丰富的生态系统,包含机器学习库(如 Ray Tune、Ray Serve 和 RLlib),适用于模型训练、超参数调优、在线服务等场景,是云原生应用和大规模计算的理想选择。
Bazel
Bazel是一种高效、可扩展的构建工具,最初由Google开发,专为管理大型代码库和复杂项目而设计。它支持多语言和多平台构建,包括C++, Java, Python, Go等,并能够跨操作系统(如Linux、macOS和Windows)执行构建任务。Bazel通过声明式的构建规则(BUILD文件)和依赖管理,实现了高性能的增量构建,避免了不必要的重复编译。其特点包括分布式构建、沙盒化执行和强大的缓存机制,可以加快构建速度并提高构建的稳定性。此外,Bazel还提供高度可配置的扩展机制,方便开发者为特定需求编写自定义规则,适合从小型项目到超大规模工程的使用场景。
gRPC
gRPC 是由 Google 开发的高性能开源 RPC 框架,基于 HTTP/2 协议,支持多语言和跨平台通信。它使用 Protocol Buffers 定义接口和序列化数据,简化了服务间的集成开发。gRPC 提供高效的请求-响应模型、流式传输、负载均衡和内置 TLS 安全特性,非常适合云原生应用、微服务架构和实时通信场景,广泛应用于分布式系统和高性能应用开发中。
cython
Cython 是一种优化的 Python 扩展语言,结合了 Python 的易用性和 C 的高性能,旨在提升 Python 代码的运行速度。通过将 Python 代码转译为 C 或 C++ 并进行编译,Cython 可以显著减少运行时的性能开销,同时支持调用 C/C++ 库,从而实现与底层代码的高效交互。Cython 保留了大部分 Python 的语法,同时允许使用 C 类型声明进行性能优化,非常适合计算密集型任务或对性能要求较高的场景,如科学计算、机器学习和数据处理。
角色
Ray集群的整体架构如下图所示
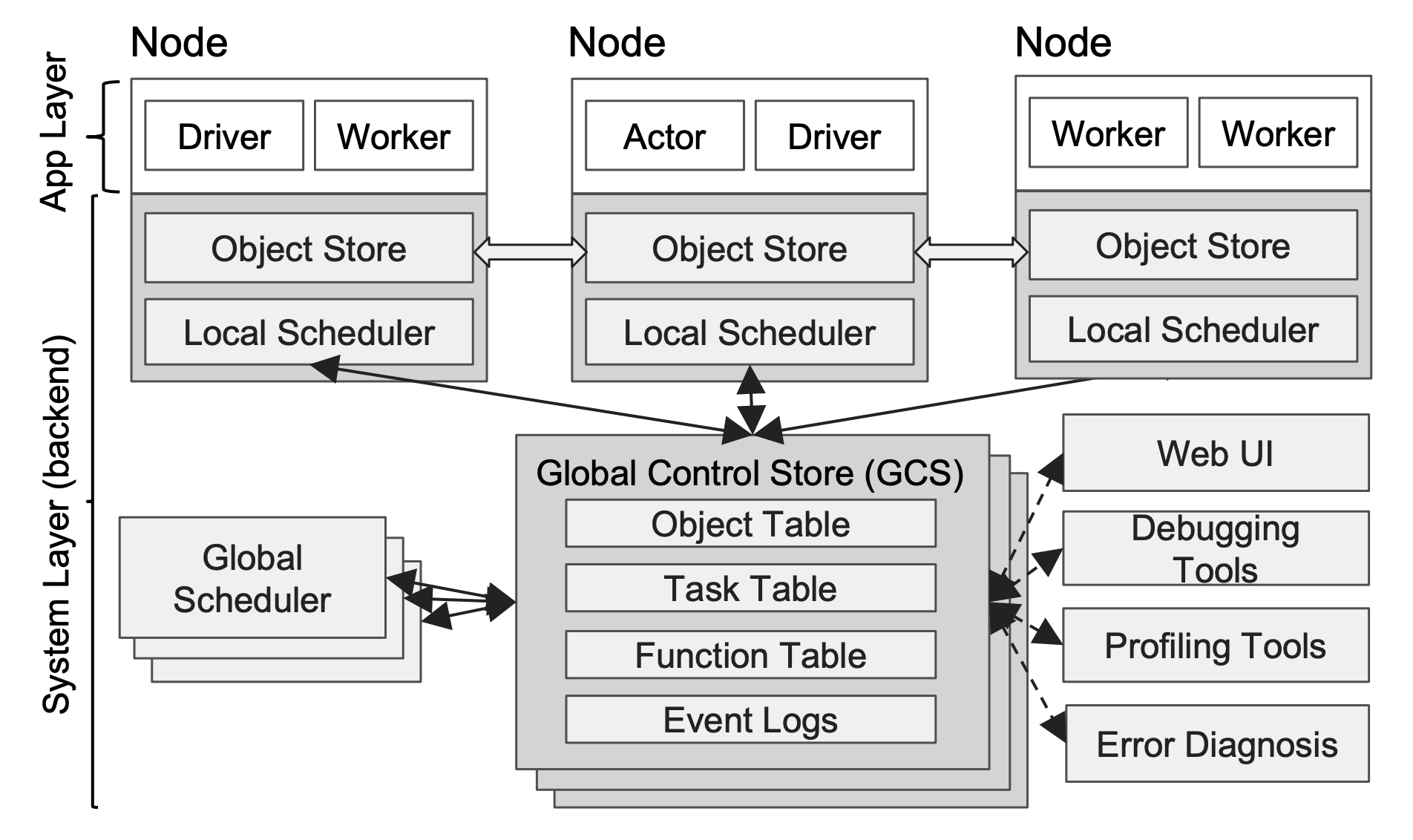
一个Ray集群包括多个Node节点,其中每个Node节点包含Actor,Worker,共享内存,本地调度器。其中Head Node还有GCS服务,包含各类元数据存储,WebUI,全局调度等功能。
Node
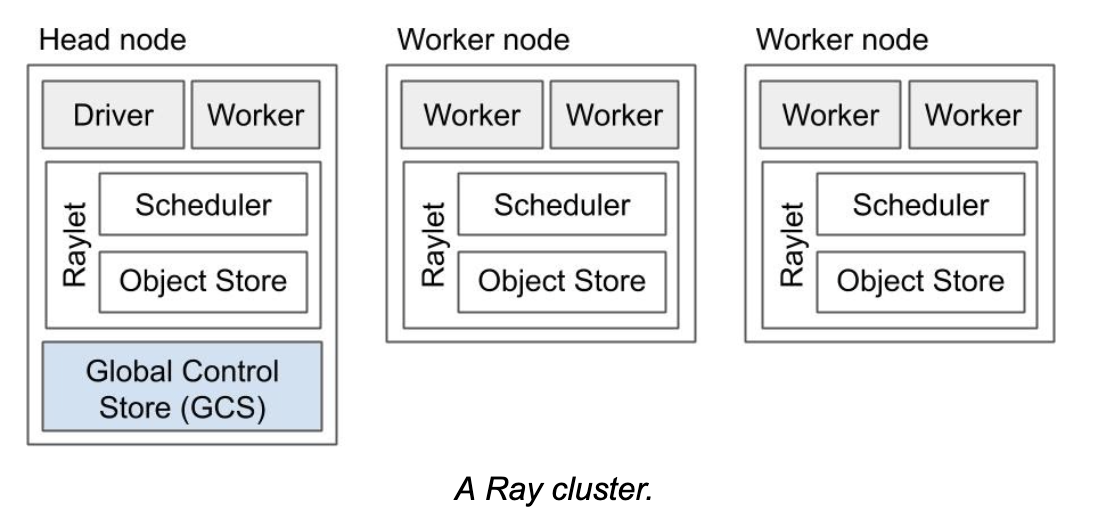
Node中包含一个Raylet进程,负责本地调度以及共享内存。Raylet会根据任务情况启动一个或者多个worker或者Actor。Head node是一个特殊的Node,除了普通Node的功能之外,还有一些外的进程,包括gcs_server服务,dashboard等。并且每个Node节点还会启动monitor进程,log_monitor进程,agent进程等。
Raylet和gcs_server是非Python进程,其他辅助进程,包括Driver,worker以及Actor均是python进程(针对Python语言而言)。
gcs_server
Ray 的 GCS Server 是 Ray
框架的核心组件,负责元数据存储、任务调度、资源管理和集群状态维护。它通过存储模块(Redis
或 内存)管理节点和任务的生命周期,使用 Pub-Sub
系统进行状态广播,并通过高效的调度协调与其他组件(如 Scheduler, Worker,
Actor 或
Object)协作,确保系统的高性能、高可用性和灵活扩展性。gcs_server是一个非Python进程,二进制文件路径在
ray/python/ray/core/src/ray/gcs/gcs_server。
raylet
Raylet 是 Ray
集群中每个节点的核心运行时组件,负责任务执行、资源管理和数据依赖协调。它接收
GCS Server 分配的任务,管理本地资源,启动 Worker 进程执行任务,并通过
Plasma Store 处理数据存储与传输。同时,Raylet 定期向 GCS Server
汇报节点状态,协作实现任务调度、资源分配和故障恢复,是 Ray
分布式运行的关键执行单元。raylet是一个非Python进程,二进制文件路径在
ray/python/ray/core/src/ray/raylet/raylet。
worker
Worker 是 Ray 中的核心计算单元,由 Raylet 启动,负责具体任务的执行和 Actor 的运行。它与 Plasma Store 协作进行数据存取,并通过与 Raylet 的通信完成任务调度和资源管理。Worker 支持多语言运行环境(如 Python、Java),能够高效并行处理任务,是 Ray 框架实现分布式计算的基础组件。
actor
Actor 是 Ray 框架中的一种状态管理单元,允许用户在分布式系统中创建带有持久状态的计算对象。每个 Actor 由一个独立的 Worker 进程运行,支持并行调用方法并维护自身状态。Actor 可以通过远程调用接口与其他组件交互,实现任务分解和动态扩展,是 Ray 中用于构建有状态应用和分布式服务的重要抽象。
driver
Driver就是用户程序(例如,用@ray.remote修饰的用户python代码),Driver负责Task的定义和提交,需要运行在Ray的Head或者Node节点上。
编译
安装Ray有多种方法,包括wheel包,pip,conda,容器镜像等。这些内容可以参考社区手册。这里介绍从源码安装。
使用Conda环境
官方推荐conda或者venv两种虚拟环境安装ray,建议选择conda。无虚拟环境将无法编译ray,并且在实测中发现了venv的未知错误。
1 | conda create -c conda-forge python=3.9 -n myenv |
安装依赖
1 | sudo apt-get update |
安装bazel
1 | ci/env/install-bazel.sh |
安装npm
用于dashboard
1 | (curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.0/install.sh) |
构建
构建dashboard
1 | cd ray/python/ray/dashboard/client |
构建ray
1 | cd ../../.. |
注意:有可能构建环境会错误的选择到gcc和lld,会导致一些奇怪的编译错误(例如,你的环境变量中存在lld,被识别,但是构建过程中并不会使用非系统路径下的lld等)。这时可以通过指定LD来解决:
在 ~/.bazelrc 中加入:build --linkopt=-fuse-ld=gold
可选的编译环境变量
RAY_INSTALL_JAVA: If set and equal to1, extra build steps will be executed to build java portions of the codebaseRAY_INSTALL_CPP: If set and equal to1,ray-cppwill be installedRAY_DISABLE_EXTRA_CPP: If set and equal to1, a regular (non -cpp) build will not provide somecppinterfacesSKIP_BAZEL_BUILD: If set and equal to1, no Bazel build steps will be executedSKIP_THIRDPARTY_INSTALL: If set will skip installation of third-party python packagesRAY_DEBUG_BUILD: Can be set todebug,asan, ortsan. Any other value will be ignoredBAZEL_ARGS: If set, pass a space-separated set of arguments to Bazel. This can be useful for restricting resource usage during builds, for example. See https://bazel.build/docs/user-manual for more information about valid arguments.IS_AUTOMATED_BUILD: Used in CI to tweak the build for the CI machinesSRC_DIR: Can be set to the root of the source checkout, defaults toNonewhich iscwd()BAZEL_SH: used on Windows to find abash.exe, see belowBAZEL_PATH: used on Windows to findbazel.exe, see belowMINGW_DIR: used on Windows to findbazel.exeif not found inBAZEL_PATH
启动一个Ray集群
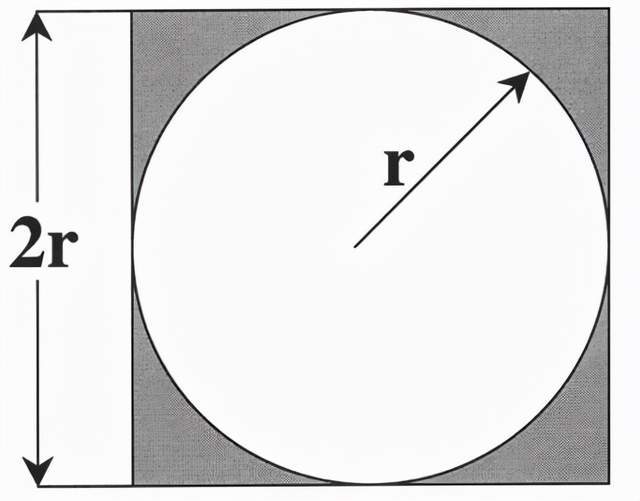
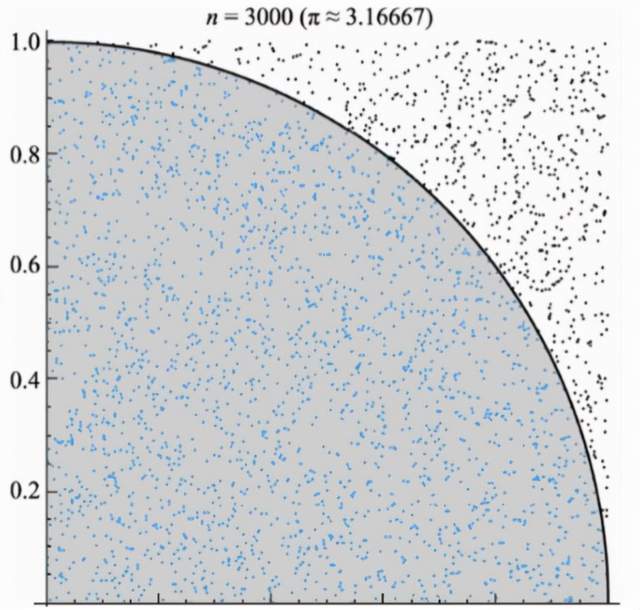
接下来使用一个简单的例子来使用Ray,这是一个使用概率计算圆周率π的程序(蒙特卡洛法)。蒙特卡洛方法在计算圆周率时设一个正方形内部相切一个圆,这时圆和正方形的面积之比是π/4。在这个正方形内部,随机产生n个点(这些点服从均匀分布),计算它们与中心点的距离是否大于圆的半径,以此判断是否落在圆的内部。统计圆内的点数,与n的比值乘以4,就是π的值。理论上,n越大,计算的π值越精确。
1 | import ray |
临时启动
如果不启动Ray集群,直接执行该Python程序,那会在当前节点上默认拉起一个ray集群供计算。
1 | python pi.py |
启动集群
启动Head节点
1 | ray start --head |
可以在http://127.0.0.1:8265查看Ray控制台。
启动Node节点
1 | ray start --address='192.168.64.8:6379' |
集群状态
1 | ======== Autoscaler status: 2025-01-21 10:54:25.170247 ======== |
启用监控
Prometheus
ray提供了一个命令来下载和部署普罗米修斯,ray提供了数据采集接口,可以让普罗米修斯通过这个接口来收集集群数据,注意,简易命令拉起的普罗米修斯不能用于生产环境,完整部署可参考官方手册。
1 | ray metrics launch-prometheus |
可以在这个地址上查看普罗米修斯状态:http://localhost:9090,可查看其采集的信息ray_dashboard_api_requests_count_requests_total。
grafana
普罗米修斯采集的数据,通过grafana的方式进行可视化显示,并且ray dashboard中的metric页面的信息也是来自于grafana。可以通过启动新的grafana服务来完成配置。
1 | cd /usr/share/grafana |
将grafana dashboard加入到已有的grafana server可以参考官方手册。
可以在这个地址上查看grafana的dashboard:http://localhost:3000
Ray dashboard
完成上述两个步骤后,Ray dashboard中的metric即可正常显示,如果不是本机部署,你可能需要配置允许所有ip访问:
1 | RAY_GRAFANA_HOST=http://192.168.64.8:3000 ray start --head --dashboard-host=0.0.0.0 |
RAY_GRAFANA_HOST的作用是让ray的dashboard能够访问到grafana服务;
--dashboard-host=0.0.0.0允许所有ip访问。
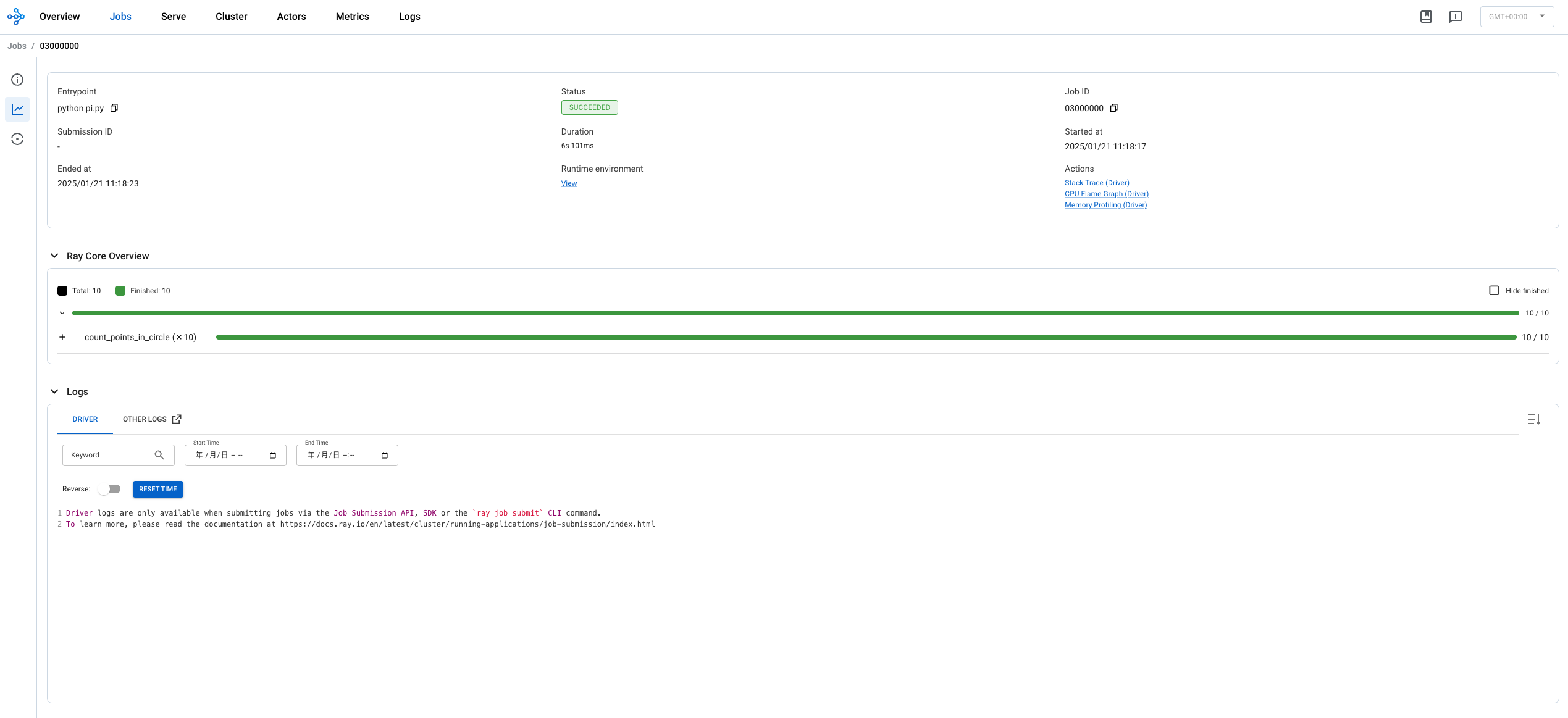
提交一个任务
1 | python pi.py |
部署一个服务
Ray除了提供基础的分布式计算能力之外,还提供了一系列的AI libs,其中可以在其上部署服务,Ray自动提供proxy和负载均衡能力。这里使用一个翻译的服务举例:
1 | from starlette.requests import Request |
具体修改方法,可以参考官方手册
直接运行这个python程序即可完成服务的部署:
1 | python translate.py |
在dashboard上可以看到服务的详情:
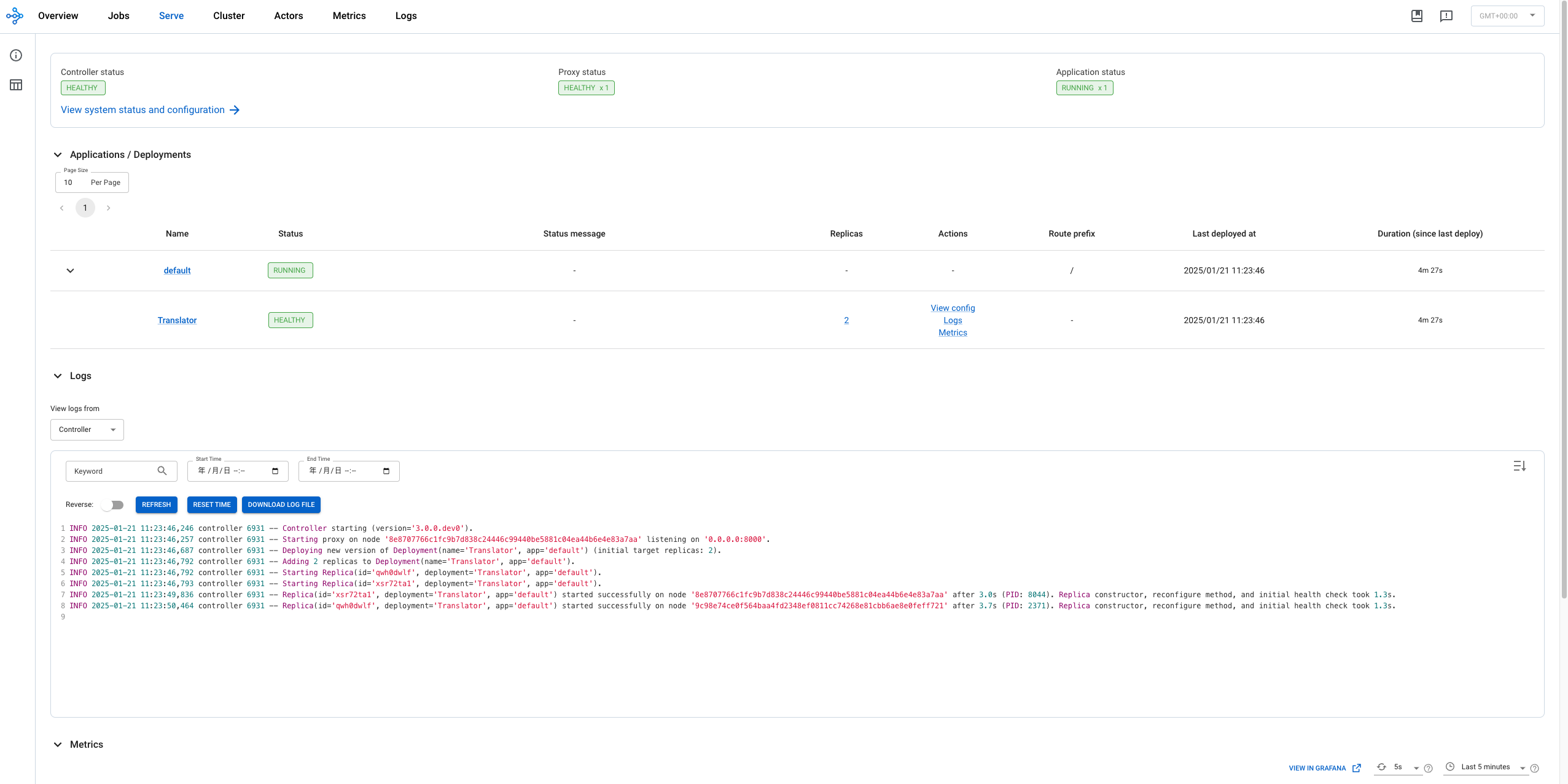

通过curl命令可以验证服务运行情况:
1 | curl -X POST http://127.0.0.1:8000/ -H "Content-Type: application/json" -d '"Hello world!"' |
调试
Ray是一个多进程,Python和C++混合调用的程序(以Python语言为例),调试上需要掌握一定的技巧。调试Python,Driver,以及自动拉起的gcs_server,raylet以及worker,actor的方法都不同。下面以VsCode为例。
调试python
Python调试与普通程序调试相同,直接点debug python文件,或者配置launch.json即可。
1 | { |
调试Driver
Driver就是用户python程序,调试Driver的Python部分参考上一节,如果调试Driver的C++部分,需要调试python进程,前提是Ray是debug编译的,否则没有符号表无法调试。
1 | { |
调试Worker或者其他进程
gcs_server,raylet,worker以及actor都是自动拉起的进程,调试的时候需要attach到这些进程上进行调试。
注意,需要接触gdb attach的限制,永久接触方法如下:
sudo vi /etc/sysctl.d/10-ptrace.conf
kernel.yama.ptrace_scope = 0
sudo sysctl --system
调试上述pi.py,在一个worker的情况下大概需要8G内存,否则会导致Ray
kill掉worker或者gdb异常退出。在调试worker过程中,为了方便,可以限制仅启动一个worker,在本地拉起的情况下,配置ray.init(num_cpus=1)。
1 | { |
worker和actor是python进程,gcs_server和reylet是非python进程,二进制在 ray/python/ray/core/src/ray/下。
gRPC流程
gRPC是什么
简单来说,RPC框架就是像调用本地函数一样调用远程函数。gRPC使用protobuf来定义服务和传输的对象,在客户端中,有一个存根(Stub),与服务有相同的函数签名,通过调用这个存根,即可完成一次RPC调用。

Ray是基于gRPC构建的分布式计算系统,有关gRPC的代码存放在 ray/src/ray/rpc目录下,下面,我们通过worker进程的gRPC服务来分析。
gRPC client
涉及到gRPC client的几个文件:grpc_client.h,
client_call.h
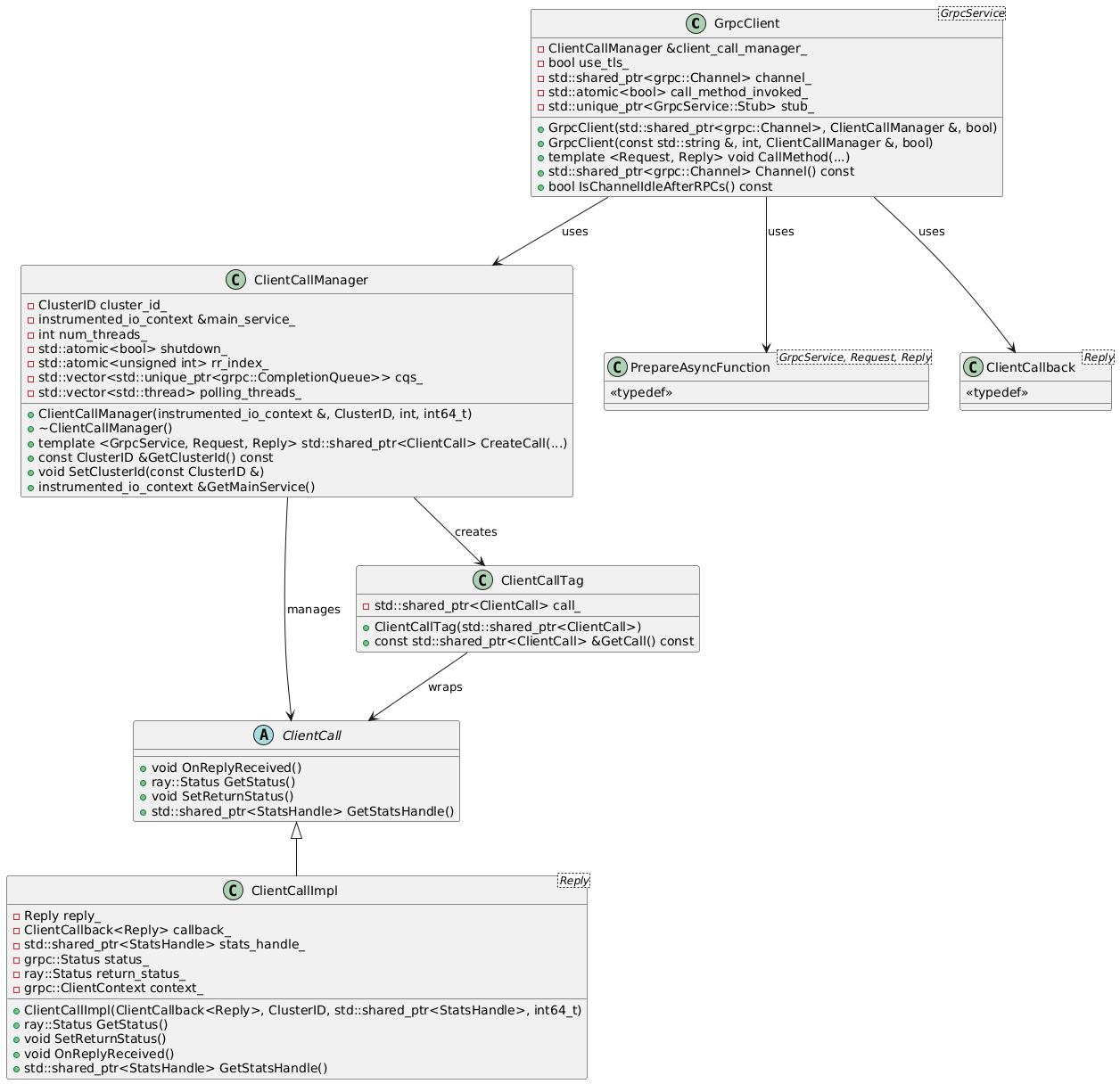
ClientCall是对RPC调用的一个封装,主要包括需要调用的stub函数指针,以及相关的状态和结果获取,当gRPC调用返回时,需要回调ClientCall中注册的回调函数。ClientCallManager是对gRPC调用发起的管理,包括结果队列,监听线程等,
GrpcClient保存的是gRPC的连接句柄,可以通过该对象发起一个gRPC请求。
对于CoreWorker来说,在此之上还有一层封装(worker/core_worker_client.h,
worker/core_worker_client_pool.h/cc),CoreWorkerClient,该类封装了CoreWorkerService可用的所用调用,直接调用提供的函数接口即可完成RPC调用。与之匹配的还有一个CoreWorkerClientPool,用于CoreWorkerClient的缓存。
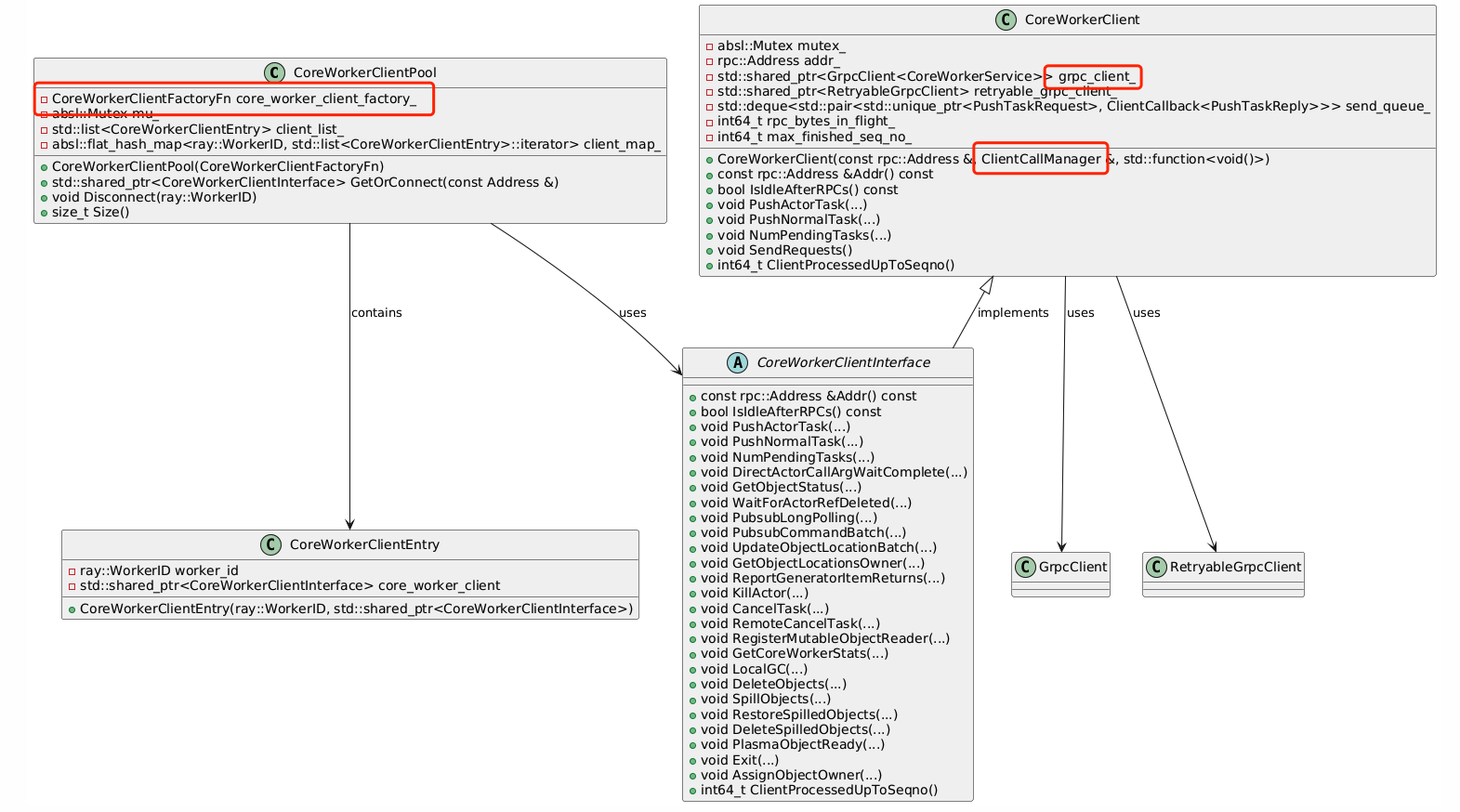
CoreWorkerClientPool维护一个map<WorkerId,
CoreWorkerClient>,当已经存在对应的CoreWorkerClient时直接取出使用。如果不存在,则调用CoreWorkerClientFactoryFn工厂方法创建一个gRPC的client连接。该工厂方法在CoreWorker的构造函数中定义,通过一个rpc::Address创建对应的CoreWorkerClient对象。
每个CoreWorkerClient对象构造过程中,会创建gRPC连接,并且通过ClientCallManager来发起RPC请求,并通过监听CompletionQueue来响应RPC的处理结果。
gRPC server
涉及到gRPC server的几个文件:grpc_server.h/cc,
client_server.h/cc
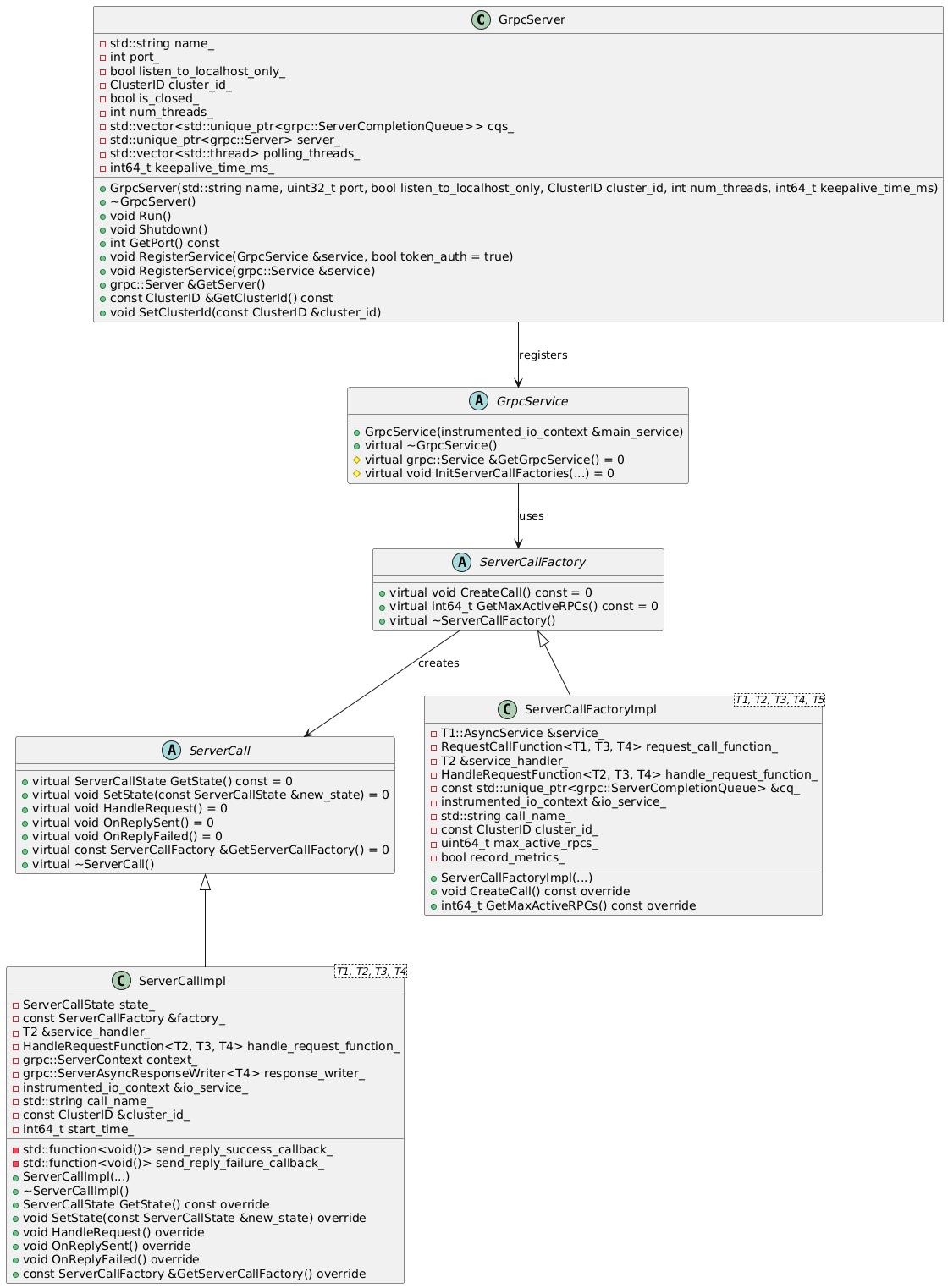
GrpcServer是gRPC的服务端,其中定义了初始化,关闭,注册服务,运行等操作。它会根据其中注册的Service来向gRPC服务中注册服务和对应的处理方法。GrpcService是一个虚拟类,其本身没有实现,需要不同的组件来继承实现,例如,CoreWorker就会用CoreWorkerGrpcService来实现一个Worker对应的Service。Service中需要提供一组ServiceCallFactory,这些Factory记录了服务,gRPC的stub,回调函数,本地异步IO组件等信息,供GrpcServer来注册对应的服务。ServiceCall即服务端服务的本身,包括一系列回调函数处理对应的事件,这个call对象会以Tag的方式放入gRPC请求中,处理时取出call对象对相应的处理。
对于CoreWorker来说,需要基于GrpcService实现GrpcCoreWorkerGrpcService(work/core_worker_server.h)。实际上的工作就是将CoreWorkerService中的服务全部注册到ServiceCallFactory中。
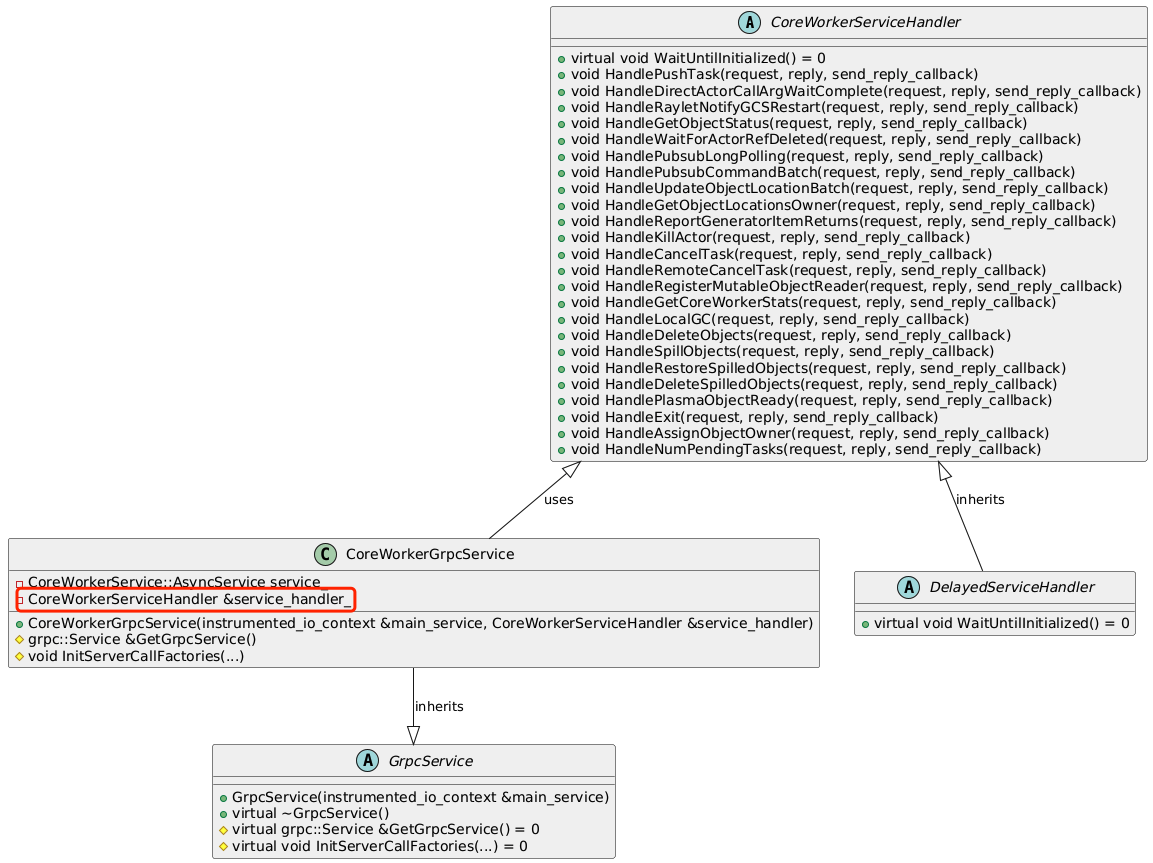
CoreWorkerServiceHandler是一组Handle方法的集合,包含CoreWorkerService中的所有服务的处理方法,CoreWorkerGrpcService中会通过一组宏来构造protobuf中的注册,响应等必要信息的对象集合(ServiceCallFactory)。
注册完成后,GrpcServer在运行之前,会将所有的事件和响应注册到队列中,这样,队列中进入事件时,就可以调用对应的处理函数进行处理。
本地异步调用
Ray使用了大量的异步处理,例如gRPC框架中的请求和响应,以及本地的异步处理框架。Ray的Worker等进程中,除了gRPC的异步框架之外,还有一个boost::asio::io_context框架,所有gRPC的响应并不是在pull_threads中处理,而是把事件转交给本地的异步处理框架,然后在该异步处理框架中处理。并且该框架中还内置了一个EventTracker,来记录所有时间的处理信息。
结果的处理交给本地异步处理来运行,猜测是为了加快gRPC队列中的数据消费。
Driver提交流程
以无状态任务为例,描述任务的提交流程。
Python部分
@ray.remote
被@ray.remote装饰的函数会被ray分布式处理。该装饰器会将函数(或者对象,后续的描述均为函数的装饰)封装成RemoteFunction对象。该对象保存了被装饰函数的function对象,并且提供remote方法。
当remote方法被调用时,会将python函数包装成PythonFunctionDescriptor,记录了module/function/class
name,以及分配的uuid。随后使用pickle_dump将函数序列化,交给worker处理。worker会将序列化后的函数存储到gcs服务的function
table中,并记录该函数的uuid,以便于通过函数描述找到函数体。
以上工作完成后,remote方法会调用worker的submit_task方法提交任务,该任务即可通过gRPC发送到集群中处理。submit_task返回一个object_ref。
1 | invocation (/home/hua/code/ray/python/ray/remote_function.py:485) |
Driver部分
任务提交到本地
Driver的python代码调用submit_task后,会通过cython调用到C++
extention中。对应的函数是CoreWorker::SubmitTask,这里会将相关的任务信息打包成TaskSpec,然后提交到本地异步IO中。
1 | _raylet.so!ray::core::CoreWorker::SubmitTask() (/home/hua/code/ray/src/ray/core_worker/core_worker.cc:2467) |
解决依赖
从异步IO调度到该任务后(NormalTaskSubmitter::SubmitTask),会先等待依赖的资源处理结束,这里使用了回调的方式异步等待依赖的任务结束。
1 | _raylet.so!ray::core::NormalTaskSubmitter::SubmitTask() (/home/hua/code/ray/src/ray/core_worker/transport/normal_task_submitter.cc:23) |
请求资源
依赖的任务执行结束后,准备执行当前任务,但是对当前SchedulingKey来说目前没有空闲的Worker,需要先向reylet请求Worker,NormalTaskSubmitter::RequestNewWorkerIfNeeded。
1 | _raylet.so!ray::core::NormalTaskSubmitter::RequestNewWorkerIfNeeded() (/home/hua/code/ray/src/ray/core_worker/transport/normal_task_submitter.cc:347) |
任务提交到集群
Worker资源异步请求会返回空闲Worker的Address,然后可以通过RPC将任务直接提交(PushTask)给这个Worker。
1 | _raylet.so!ray::rpc::CoreWorkerClient::PushNormalTask() (/home/hua/code/ray/src/ray/rpc/worker/core_worker_client.h:399) |
Worker执行流程
调试技巧
- 首先启动Driver,在
INVOKE_RPC_CALL执行之前打断点,阻塞任务提交到集群。 - attach到Worker进程上,并且在
CoreWorker::HandlePushTask打断点,这里是处理RPC请求的入口。 - 让Driver继续执行,Worker就会命中断点,可以继续调试Worker。
gRPC将任务提交到本地
GrpcServer::PollEventsFromCompletionQueue会等待gRPC请求,当收到请求后,就会调用从Tag中取出ServerCall对象,该对象中保存着该请求的所有处理的必要信息。然后将该任务提交给异步IO。
1 | _raylet.so!ray::rpc::ServerCallImpl<ray::rpc::CoreWorkerServiceHandler, ray::rpc::GetCoreWorkerStatsRequest, ray::rpc::GetCoreWorkerStatsReply, (ray::rpc::AuthType)0>::HandleRequest() (/home/hua/code/ray/bazel-out/aarch64-dbg/bin/_virtual_includes/grpc_common_lib/ray/rpc/server_call.h:237) |
调用gRPC注册的Handler方法
异步IO会回调注册的方法CoreWorker::HandlePushTask,配置定义send_reply_callback回调函数,最后将任务通过异步IO提交给task_execution_service(就是另外一个异步IO队列)。
执行函数
当执行调度到PushTask任务时,就会回调上一步配置的send_reply_callback回调,远程函数的执行就在这个回调中运行
1 | _raylet.so!operator()(const struct {...} * const __closure, const ray::TaskSpecification & task_spec, ray::rpc::SendReplyCallback send_reply_callback) (/home/hua/code/ray/src/ray/core_worker/transport/task_receiver.cc:100) |
回调中的task_handler_
就是注册进去的CoreWorker::ExecuteTask,将这个对象封装成了一个lamda函数:
1 | auto execute_task = std::bind(&CoreWorker::ExecuteTask, |
最终调用到了options_.task_execution_callback,这个callback会根据语言的不同而不同,以Python为例,这个callback调用的是注册进来的一个Python方法,将Python的远程函数交还给Python解释器来执行。这部分代码在ray/python/ray/_raylet.pyx中
1 | cdef void execute_task: return function(actor, *arguments, **kwarguments) |