llama.cpp昇腾原生支持
1. 项目背景
llama.cpp 是一个开源项目,旨在将大模型高效地部署在低资源环境中,例如个人电脑或移动设备。这个项目由 Georgi Gerganov 创建,目标是通过优化和精简,使得 LLaMA 模型能够在不依赖 GPU 的情况下高效运行。llama.cpp 支持多平台和多后端,且兼容大部分 Transformer 模型和部分 CLIP 模型,便于在各种环境中部署。其模块化设计包括模型分片、KV 缓存、推理引擎和输出处理,适合边缘计算、隐私保护和低成本推理场景,帮助用户在普通设备上实现大模型推理。
1.1 目标
开发基于昇腾的llama.cpp后端,实现昇腾runtime和核心算子。后端使用CANN和昇腾算子库的能力来加速大模型的推理。使得常见的模型能够在llama.cpp中使用昇腾推理,加速推理效率。
1.2 项目概述
昇腾后端和Runtime接入
在 llama.cpp 中,为Ascend加速器提供接口适配层,使 llama.cpp 的模型推理请求能通过接口层传递至 Ascend Runtime。
涉及:
- 设备接入,支持多卡接入;
- 内存管理和Tensor管理;
- Stream,Event管理;
昇腾算子
为了支持大部分的模型推理,需要实现43个算子。这些算子可以利用aclnn的算子能力构建,如果aclnn的算子不足以满足llama.cpp的算子,
则:
- 优先使用aclnn算子组合的方式实现功能;
- 使用AscendC编写自定义算子。
对算子的需求,可用性大于性能,为了减少开发工作量并快速完成支持,不考虑acl op算子。能使用aclnn组合的算子,优先使用算子组合实现。
精度和性能
实现的算子需要通过llama.cpp的精度对比测试,以及内存越界检查,确保实现的算子实现正确。
910B算子性能需要超过Intel CPU水平(以Intel(R) Xeon(R) Gold 6348 CPU @ 2.60GHz为例)。
910B模型推理(llama3 8B)性能延迟不高于100ms,吞吐率不低于300token/s。
多芯片支持
- 首先支持910B系列芯片,包括主要的模型端到端推理,q4_0,q8_0量化格式;
- 然后支持310P(910A)系列芯片,除了q4_0外(310P不支持4bit量化),其他功能应当与910B芯片能力持平;
- 最后尝试支持310B系列芯片,310B的支持程度以aclnn和AscendC库的支持情况而定。
文档和用户指南
用户指南,介绍文档结构和使用说明,帮助用户理解如何在 llama.cpp 中配置和使用 Ascend 后端;
安装配置步骤,详细说明 Ascend 后端的安装流程,包括环境依赖、编译步骤及配置方法,以确保用户可以顺利完成安装;
常见问题和解决方法,总结用户在使用 Ascend 后端时可能遇到的问题,并提供解决方案,如内存溢出、兼容性问题和性能调优建议等。
2. 设计思路
2.1 llama.cpp项目架构

llama.cpp的核心功能主要涉及以上几个部分:
模型管理
llama.cpp不仅支持llama,而且支持多种大语言模型和一些clip模型。llama.cpp使用模型管理模块来搭建模型结构,包括算子,量化等并且加载gguf模型的信息和模型权重。由于llama.cpp支持模型拆分的功能,以便于支持多卡推理和GPU/CPU混合推理,所以模型结构会进行合适的拆分,并且管理子图之间的数据拷贝。
kv-cache
kv-cache有助于加速attention的计算速度,将历史的kv信息做缓存。kv-cache会直接当做算子融合到模型中,kv-cache模块本身负责cache的管理,包括cache写入,更新和替换。
server和api接口
llama.cpp提供了一个简单的服务端,提供api接口。server支持并发推理。
推理引擎
llama.cpp对推理引擎进行了抽象,以便于支持不同的后端。推理引擎负责管理设备的内存,流,事件,多卡以及GPU/CPU数据拷贝。并且计算由模型管理模块构建的模型图。
2.2 昇腾后端接入方法
llama.cpp提供了一系列抽象接口来接入后端加速器:
ggml_backend_cann_device_interface:用于描述设备接口的模块,定义了设备的基本功能。ggml_backend_cann_interface:用于管理后端通用接口的模块,包含常见的张量异步处理和图计算功能。ggml_backend_cann_buffer_type_host:负责分配主机缓冲区,确保与后端设备内存的接口兼容。ggml_cann_compute_forward:主计算模块,负责分派和执行各个算子操作。
在 ggml_cann_compute_forward 中,所有的算子都作为 case
分支进行注册,表示算子名称对应具体操作,例如
GGML_OP_ADD、GGML_OP_MUL 等等。
昇腾接入需要实现llama.cpp的runtime接口,并且实现推理所必须的算子。
3. 实现原理
3.1 运行时
runtime提供了多个抽象接口,第一阶段主要目标是基本功能支持,所以仅需要支持必要的接口。其中split tensor功能和图推理功能暂时不实现。llama.cpp的后端接入主要是通过注册三组接口实现,分别是设备访问接口,资源管理接口,内存管理接口。
1 | static const ggml_backend_device_i ggml_backend_cann_device_interface = { |
此接口 ggml_backend_cann_device_interface 为 CANN 后端在
llama.cpp 中提供了一个通用的设备访问与操作抽象层,便于整合并统一管理
CANN 设备资源。通过实现接口中的各个函数,用户可以控制 CANN
设备的初始化、资源分配、操作支持检测等关键功能,从而确保 llama.cpp
中的模型计算能够顺利利用 CANN 的加速能力。
以下是接口中各函数的功能描述:
ggml_backend_cann_device_get_name:返回设备的名称,用于识别不同的设备类型。例如可以返回 "CANN 设备" 或者具体的设备型号。
ggml_backend_cann_device_get_description:返回设备的详细描述信息,通常包含设备的硬件特性以及版本信息等,帮助用户理解设备特性。
ggml_backend_cann_device_get_memory:获取设备的内存信息,包括总内存大小和当前可用内存,以便 llama.cpp 优化内存分配策略。
ggml_backend_cann_device_get_type:返回设备类型,用于区分不同种类的设备(如 CPU、GPU、NPU 等),便于进行不同类型设备的适配。
ggml_backend_cann_device_get_props:获取设备的属性信息,包括计算能力、内存带宽等。这些属性信息可用于优化计算分配和选择适合的算子。
ggml_backend_cann_device_init:初始化后端设备,确保设备的资源和状态准备就绪。这一步通常在加载模型或开始计算之前调用。
ggml_backend_cann_device_get_buffer_type:返回设备内存缓冲区的类型信息,帮助 llama.cpp 决定如何在设备端管理数据缓冲。
ggml_backend_cann_device_get_host_buffer_type:返回主机端缓冲区类型,用于在主机和设备之间进行高效的数据交换。
buffer_from_host_ptr:该接口可用于将主机端内存直接映射或转换为设备端缓冲区,若未来需求可扩展。
ggml_backend_cann_supports_op: 检查 CANN 设备是否支持指定的操作(op),确保模型中的特定操作能够得到设备的加速支持。
ggml_backend_cann_supports_buft:检查设备是否支持指定的缓冲区类型,确保数据在缓冲区类型上的一致性和兼容性。
ggml_backend_cann_offload_op:将计算操作卸载到设备端执行,提升操作效率和加速模型推理过程。
ggml_backend_cann_device_event_new:创建新的事件对象,用于异步操作的状态跟踪,如操作完成的通知。
ggml_backend_cann_device_event_free:释放事件对象,清理事件资源,确保内存不被泄漏。
ggml_backend_cann_device_event_synchronize:同步事件,确保指定的异步操作完成。这通常用于确保操作的执行顺序。
1 | static const ggml_backend_i ggml_backend_cann_interface = { |
ggml_backend_cann_interface 接口提供了 CANN 后端在
llama.cpp 中的资源管理、异步数据传输、计算图执行等功能接口,实现了与
CANN 后端的深度集成。通过该接口,llama.cpp
可以高效地管理张量的异步操作、事件记录、同步及图计算,确保计算任务能够顺畅运行在
CANN 设备上。
以下是接口中各函数的功能描述:
ggml_backend_cann_name: 返回后端名称,通常用于标识该后端为 CANN 后端。
ggml_backend_cann_free:释放后端资源,确保内存和其他资源在后端不再使用时被正确回收。
ggml_backend_cann_set_tensor_async:异步设置张量数据到设备端,为后续计算提供数据准备。异步设置可提高数据传输的效率。
ggml_backend_cann_get_tensor_async :异步获取张量数据,方便在计算完成后从设备端提取数据,避免阻塞主线程。
ggml_backend_cann_cpy_tensor_async:异步复制张量数据,支持设备端和主机端之间的数据交互或设备内部的数据拷贝,以便于多任务并行处理。
ggml_backend_cann_synchronize :同步操作,确保所有异步任务完成,通常用于确保张量操作和事件顺序执行。
graph_plan_create:该接口目前未实现。将来可用于创建计算图执行计划,优化计算图的操作顺序和资源分配。
graph_plan_free:该接口目前未实现。可以释放计算图计划的资源,确保内存使用的高效管理。
graph_plan_update:该接口目前未实现。可用于在图执行过程中动态更新计算计划,以适应运行时的资源情况。
graph_plan_compute:该接口目前未实现。未来可能用于执行图计划中的所有操作,便于更复杂的任务调度。
ggml_backend_cann_graph_compute:执行计算图中的所有节点操作,是核心计算接口之一。该函数负责协调图中的计算任务,使之并行或顺序执行。
ggml_backend_cann_event_record:记录事件,用于标记特定操作的时间点,便于在异步计算中追踪进度和执行状态。
ggml_backend_cann_event_wait:等待特定事件完成,通常用于确保在后续操作开始前当前任务已完成,以保持计算图的执行正确性。
1 | static const ggml_backend_buffer_type_i ggml_backend_cann_buffer_type_interface = { |
ggml_backend_cann_buffer_type_interface 结构体定义了
CANN
后端缓冲区类型的接口,它提供了一组操作缓冲区属性和行为的函数接口。这个接口使得
CANN 后端的缓冲区能够在 llama.cpp
中被正确管理和使用,确保内存分配、对齐、大小等操作的一致性和高效性。
以下是 ggml_backend_cann_buffer_type_interface
结构体中各字段的功能描述:
- ggml_backend_cann_buffer_type_name:返回缓冲区类型的名称。该函数用于标识当前缓冲区类型,主要用于调试和日志记录。
- ggml_backend_cann_buffer_type_alloc_buffer:用于分配缓冲区的内存。通过该函数,llama.cpp 可以请求 CANN 后端分配指定大小的内存块,用于存储数据和张量。
- ggml_backend_cann_buffer_type_get_alignment:返回缓冲区的对齐方式。内存对齐对于性能至关重要,因为不适当的对齐可能导致 CPU 或 GPU 在访问数据时的效率降低。该函数可以确保数据在内存中的对齐符合硬件的要求。
- get_max_size :该字段指示缓冲区的最大尺寸,若设置为
NULL,则默认最大值为SIZE_MAX,即没有固定的尺寸限制。此函数适用于不希望为缓冲区大小设定上限的场景。 - ggml_backend_cann_buffer_type_get_alloc_size :获取缓冲区实际分配的内存大小。该函数确保返回正确的分配大小,便于用户跟踪内存使用情况。
- ggml_backend_cann_buffer_type_is_host:判断缓冲区是否为主机缓冲区。该函数用于区分主机内存和设备内存,以便进行适当的内存管理和数据传输。
Host buffer
Host buffer是一种特殊的buffer type,用于在CPU上申请内存,用于一些中间数据的临时存储,为后端设备提供了以快速访问的内存区域。
Pin memory,又称“锁页内存”或“固定内存”,是指将主机内存中的一部分内存固定在物理内存上,以便快速传输至计算设备(如GPU或NPU)。通常情况下,操作系统会将不经常使用的内存页移至虚拟内存中,这可能导致数据传输时出现额外的内存访问延迟。而使用Pin memory则可以避免这种情况,因为锁页内存不会被系统交换出物理内存,从而大大加速数据传输过程。
Host buffer使用Pin memory实现,用户加速Host和Device之间的内存拷贝速度。Host buffer与buffer_type的结构相同,以接口注册的方式提供Host buffer的能力。
Split Tensor
Split Tensor用于在做复杂计算的时候充分利用多卡能力,llama.cpp中,对矩阵乘法,使用到了Split Tensor,计算时会相乘的矩阵其中一个进行拆分,使用多卡进行并行计算,计算完成后做结果的合并。
Split Tensor实现复杂,并且无法利用已有的aclnn算子,在本次设计中不考虑,待后续性能提升中考虑实现。
3.2 算子
llama.cpp主要的推理是单算子推理功能,图推理功能在本次设计中暂不考虑实现。昇腾的单算子支持aclop以及aclnn两种调用方式。经过简单的demo进行性能对比,aclop编译执行的方式执行效率较低,主要算子均通过aclnn实现,aclnn不支持的算子使用aclnn基本算子组合的方式实现,后续需要使用AscendC将组合算子进行融合以提高性能。
3.2.1 Tensor转换
llama.cpp和昇腾算子对Tensor的定义有一定的差异,为了能够使用昇腾算子,需要在调用的时候对Tensor结构做转换。
结构差异
两者的Tensor基本上都是数据和dims,nelements,nstride,dtype的属性集合,但是有一些差异:
- llama.cpp的ne和nb的顺序是从内到外,也就是与传统意义的维度顺序相反,序号小的是最内的维度。
- llama.cpp的stride的单位是字节,而aclnn的stride单位是元素。
广义broadcast
当两个计算的tensor维度不同时,会尝试做broadcast,aclnn接口支持的是传统broadcast方式,而llama.cpp支持的是广义的broadcast:
- aclnn接口的broadcast仅会在Tensor的某个维度不同,但是其中一个Tensor的维度为1的时候发生;
- llama.cpp的broadcast会在Tensor的某个维度不同,但一个Tensor的维度大小是另外一个的整数倍的时候发生。
为了减少显示broadcast带来的性能和内存的开销,需要进行维度的调整,以便于利用算子的broadcast特性:
例如,Tensor A(9,5,2,7), Tensor B(9,10,2,7),这两个Tensor对aclnn接口来说不可自动broadcast,但是对llama.cpp来说允许自动broadcast。当数据内容连续时,可以通过添加一个维度来兼容aclnn的broadcast规则。 通过将 A(9,5,2,7)转换成A'(9,5,1,2,7),B(9,10,2,7)转换成B'(9,5,2,2,7)。仅通过调整dims信息,即可利用aclnn算子的自动broadcast能力。
3.2.1 aclnn算子
| 算子名称 | 描述 | 计算公式 |
|---|---|---|
| Elementwise Add | 对两个张量进行逐元素加法,并将结果存储在目标张量中。 | \(dst(i)=src0(i)+src1(i)\) |
| Leaky ReLU | 对输入张量应用 Leaky ReLU 激活函数,并将结果存储在目标张量中。 | \[\text{dst(i)} =\begin{cases}\text{src(i)} & \text{src(i)} \geq \text{0} \\\text{negative-slope} \times \text{src(i)}& \text{src(i)} < \text{0}\end{cases}\] |
| Arange | 创建一个从 start 开始,到 stop
结束,每次增长 step 的 Tensor。 |
\(\text {out }_{i+1}=\text {out }_i+\text {step}\) |
| Clamp | 将 input 张量的每个元素夹紧到区间 [min, max] 中,并将结果返回到新的张量中。 | \[ \text{dst}(i) = \begin{cases} \text{min} & \text{src(i)} < \text{min} \\ \text{src(i)} & \text{min} \leq \text{src(i)} \leq \text{min} \\ \text{max} & \text{src(i)} > \text{max} \end{cases} \] |
| Scale | 使用 scale 缩放一个 Tensor
的所有元素,将结果返回到新的张量中。 |
\(dst(i) = src(i) \times scale\) |
| Argsort | 将输入 Tensor 中的元素根据某个维度进行升序 / 降序排序,返回对应的 index 值。 | - |
| Layer Norm | 对指定层进行均值为 0、标准差为 1 的归一化计算,并将结果写入到新的张量中。 | \(out = \frac{x - E[x]}{\sqrt{Var[x] + \epsilon}} \times w + b\) |
| Group Norm | 计算输入的组归一化结果返回到新的张量中。 | $ out &= + \$ |
| Acc | 将 src 张量的数据累加到 dst 中。 | \(dst(i) = src(i) + dst(i)\) |
| Sum Rows | 返回给定维度中输入张量每行的和。 | - |
| Upsample Nearest2d | 对由多个输入通道组成的输入信号应用最近邻插值算法进行上采样。 | - |
| Pad | 将 Tensor 填充到与目标 Tensor 相同的尺寸。 | - |
| avg pool2d | 对输入 Tensor 进行窗口为 kH×kW、步长为 sH×sW 的二维平均池化操作。 | \[\text{out}\left(N_{i}, C_{i}, h, w\right) = \frac{1}{k H \cdot k W} \sum_{m=0}^{k H-1} \sum_{n=0}^{k W-1} \text{input}\left(N_{i}, C_{i}, \text{stride}[0] \times h + m, \text{stride}[1] \times w + n\right)\] |
| max pooling | 对于 dim=3 或 4 维的输入张量,进行最大池化操作。 | \(\text{out}\left(N_{i}, C_{i}, h, w\right) = \max_{m=0}^{k H-1} \max_{n=0}^{k W-1} \text{input}\left(N_{i}, C_{i}, \text{stride}[0] \times h + m, \text{stride}[1] \times w + n\right)\) |
| rms norm | 计算给定 Tensor 的均方根归一化函数,并将结果写入到输出 Tensor 中。 | \(\text{RmsNorm}\left(x_i\right)=\frac{x_i}{\text{Rms}(\mathbf{x})} g_i,<br/> *\quad \text { where } \text{Rms}(\mathbf{x})=\sqrt{\frac{1}{n} \sum_{i=1}^n x_i^2+e p s}\) |
| diag mask | 将 Tensor 进行三角形掩码运算,将下三角部分保留,上三角部分置 1。 | - |
| img2col | 用于将二维 Tensor 数据转换成矩阵形式,以便于高效地进行卷积运算。 | - |
| timestep_embedding | 用于生成时间步嵌入。 | \(\text{dst}(t) = [\sin(\frac{t}{10000^{2i/d}}), \cos(\frac{t}{10000^{2i/d}})]\) |
| softmax | 将输入的张量转化为概率分布,其值范围在 [0, 1] 之间,总和为 1。 | $ (x_i) = $ |
| matmul | 计算两个 Tensor 的矩阵乘法,结果返回到新的 Tensor 中。 | $ C_{ij} = {k=1}^{n} A{ik} B_{kj}$ |
| Rope | 算子是一种位置编码方法,通过旋转操作为输入序列引入位置信息,增强模型对位置关系的感知能力。 | \(\text{ROPE}(q, k) = \left[ q_{\text{even}} \cos(\theta) - q_{\text{odd}} \sin(\theta), ; q_{\text{odd}} \cos(\theta) + q_{\text{even}} \sin(\theta) \right]\) |
| repeat | 对输入张量的元素沿特定维度重复,扩展原始数据的维度或增加相同数据的次数。 | \(\text{repeat}(x) = [x, x, \dots, x] \quad (\text{repeated along specified dimension})\) |
| concat | 将两个或多个张量在指定维度上拼接。 | \(\text{concat}(x_1, x_2, \dots, x_n) = [x_1, x_2, \dots, x_n] \quad (\text{along specified dimension})\) |
| Cast | 将张量的数据类型从一种类型转换为另一种类型。 | - |
| permute | 重新排列张量的维度顺序。 | - |
| exp | 对 Tensor 的每个元素执行 exp 指数运算。 | \(\text{dst}_i = e^{\text{src}_i}\) |
| Elementwise Mul | 对两个张量对应元素进行乘法运算。 | \(z = x \times y\) |
| Cos | 对张量的每个元素计算余弦值。 | \(y = \cos(x)\) |
| Sin | 对张量的每个元素计算正弦值。 | \(y = \sin(x)\) |
| fill scalar | 将张量的所有元素填充为指定的标量值。 | \(x[:] = \text{scalar}\) |
| pow tensor | 将一个张量的每个元素提升到对应的指数幂。 | \(y = x^{\text{power}}\) |
| Alibi | 一种相对位置嵌入策略,在注意力分数中加入线性偏置,帮助捕获相对位置信息。 | $(i, j) = -m |
| repeat interleave | 对张量的每个元素按指定次数重复,以在张量中插入更多的副本。 | \(\text{dst}(x, \text{repeats}) = [x_1, x_1, \dots, x_1, x_2, x_2, \dots, x_2, \dots]\) |
| roll | 将张量元素沿指定维度循环移动,即滚动。 | \(\text{roll}(x, \text{shift}) = x_{\text{shifted along axis}}\) |
| index fill tensor | 在张量的特定索引位置填充指定值。 | \(dst[\text{index}] = \text{src}\) |
3.2.2 AscendC算子
以下算子没有aclnn接口可调用,也无法使用基础算子组合,需要通过AscendC编程语言实现。为了简化算子的调用流程,采用kernel
call的方式进行调用。AscendC算子独立编译,以.a的方式链接到llama.cpp中。
dup
dup和copy语义相同,均为Tensor之间的拷贝,需要支持:
- 量化Tensor和非量化Tensor之间的拷贝,拷贝过程中涉及到量化和反量化的计算过程。需要支持Q4_0和Q8_0两种量化格式。非量化格式需要支持fp32和fp16两种格式。
- 连续Tensor和非连续Tensor之间的拷贝(量化格式Tensor不涉及非连续场景)。
get rows
从Tensor中按照index获取每行内容。
需要支持多种数据格式,包括fp32,fp16,Q4_0和Q8_0。获取后的数据均为fp32格式。
AscendC算子通过kernel launch的方式调用,调用时需要判断AI core的数量,来配置合适的数量以提升执行效率。
为了兼容多种芯片,CMake时需要检测或根据提供的芯片类型进行编译和链接。
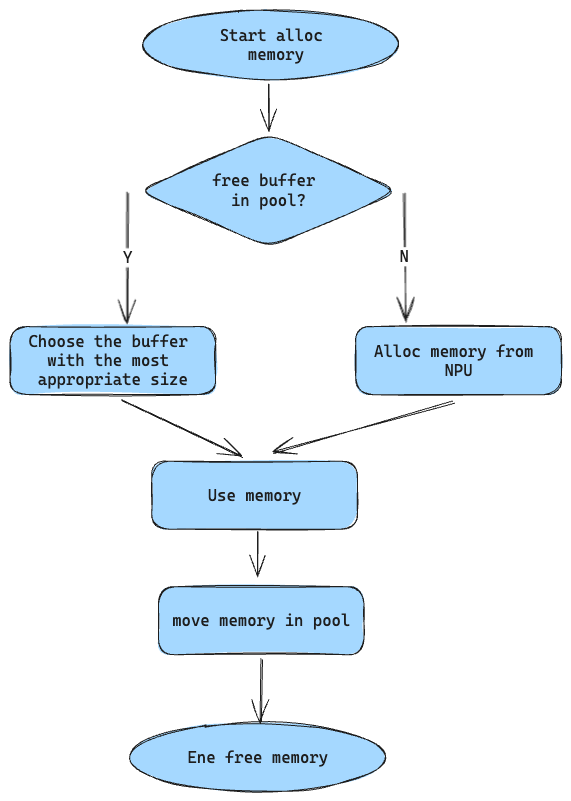
3.3 内存管理
aclnn执行时,有些需要申请临时的NPU上内存做临时数据存储,频繁的内存分配和释放效率很低,需要内存池来提高内存分配性能。
在llama.cpp中,需要实现2中内存池:
legacy pool
使用N(256)个buffer做内存缓存,所有的内存释放必须放回内存池(防止异步执行访问到已释放内存),内存申请首先选择内存池中大小最合适的缓存,内存池为空则去申请内存。
会占用额外的内存,并且存在内存块查找的开销,并且,如果free的内存块超过N(256),则会出现assert失败问题。
vmm pool
使用虚拟内存,业务代码看到的是一段连续的内存,方便使用。实际上申请的物理内存是非连续的,当内存不足时申请一段物理内存映射到虚拟内存中。避免内存碎片和占用额外内存。
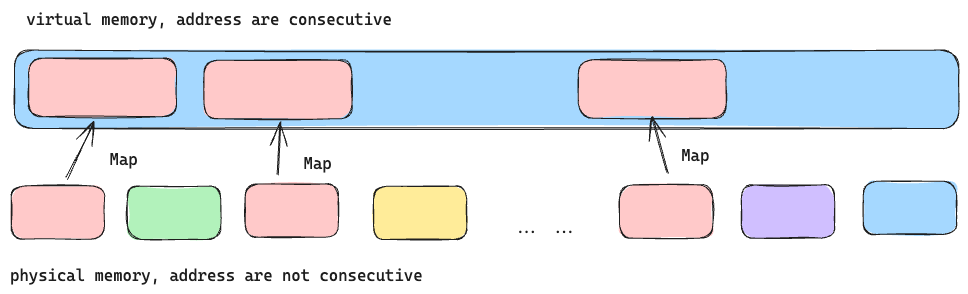
在虚拟内存中,申请的数据紧密排列,申请和销毁的顺序是相反的。比如,buffer1早于buffer2申请,那么buffer2必须要早于buffer1释放。在内存管理中,仅维护一个free指针,指示下一个buffer申请的起始地址。

异步计算的内存延迟释放
由于所有的算子计算都是异步的,但是内存的申请和释放并不是异步的,所以,需要保证在异步计算完成之前,申请的内存是有效的。

如图所示,当算子提交完成后,buffer3就会释放,free指针指向buffer3的起始地址。接着,下个算子开始执行,会从free指针开始申请内存,此时buffer3和buffer4是重叠的,但是由于stream中的算子计算有序,所以buffer3内的数据在完成计算之前,是不会被buffer4修改的。
3.4 量化格式
以4bit量化为例:
量化分组格式
1 |
|
量化算法描述
1 | void quantize_row_q4_0_reference(const float * restrict x, block_q4_0 * restrict y, int64_t k) { |
NPU善于做向量和矩阵计算,按字节的计算,以及位计算性能不佳。 所以需要调整数据存储格式。
在set tensor过程中,使用cpu做tensor的内存调整,让后续的计算能够充分利用NPU能力。

如上图所示,输入的Tensor是按组存放的,每组存放了该组的公共系数,以及32个数据的量化后的值,int4类型量化值是先填充高4位,再填充低4位。为了昇腾的计算效率,在做这类伪量化算法时,将原始Tensor拆解成2个Tensor,一个按顺序记录所有的值,另外一个记录每一组的公共系数,并且值和公共系数按32:1的方式对应。然后昇腾算子按照weight和group scale的方式输入进算子,能够提高量化后Tensor的执行效率。
所有的内存布局修改的时机是set tensor和get tensor过程中,对于整个程序来说,对内存布局的修改是不感知的,拷贝到NPU上时进行布局修改,从NPU下载时再进行布局复原,这样,及时设计CPU,NPU混合运算,也不会影响数据的正确性。
对于更加复杂的量化方式,例如q5_0,需要设计到位运算,此类量化由于性能问题尚未支持。
3.5 代码风格和注释
llama.cpp社区对代码风格没有详细的要求,社区仅要求”清除所有尾随空格,使用
4 个空格缩进,括号在同一行void * ptr,int &
a`”。并且,对注释也没有明确的要求。为了能够保持一致的风格,以及方便社区开发者了解昇腾后端的业务逻辑,需要在编写代码时遵循一致的编码规范和详尽的注释。
- 除了社区要求的内容之外,其他代码规范需要遵循google编码规范;
- 注释需要包含函数和变量的介绍,参数和返回值说明,算子相关代码需要注释算法的数学公式。其他的复杂逻辑按需求添加注释;
- 注释需要符合doxygen风格,以便于生成方便阅读的手册。
4. 测试和验证
本设计文档主要是昇腾的后端支持,llama.cpp已经做了后端抽象,所有测试用例可以复用社区的内容。针对社区用例没有看护到的部分,添加必要的用例来看护。
4.1 Runtime测试
Runtime测试主要是验证设备注册,内存分配,stream和event管理相关功能。
设备注册和卸载(单卡,多卡)
测试目的
- 验证昇腾设备可以正常注册到llama.cpp中,支持单卡和多卡注册。
测试步骤
- 调用设备注册接口,注册单卡以及多卡;
- 查看设备信息是否正常获取。
预期结果
无报错信息,并根据ASCEND_VISIBLE_DEVICES的设置情况,能够正常获取到对应的设备信息。
buffer和Tensor创建
测试目的
- 验证昇腾后端可以正常的创建buffer以及llama.cpp的Tensor结构;
测试步骤
- 构造若干个Tensor结构,并给这些Tensor分配内存buffer;
预期结果
- 内存完成分配,无错误信息。
Tensor的上传和下载(同步,异步)
测试目的
- 验证数据可以正确的上传和下载。
测试步骤
- 构造随机数据;
- 将数据拷贝到创建好的Tensor中;
- 将Tensor中的数据下载;
- 与原始随机数据进行对比。
- 分别使用同步拷贝和异步拷贝,重复以上过程。
预期结果
- 数据比对与原始数据相同。
Tensor卡间拷贝(包括event同步)
测试目的
- 验证卡间拷贝以及事件同步的正确性。
测试步骤
- 构造随机数据;
- 将数据拷贝到卡1的Tensor中;
- 开启卡1和卡2的卡间拷贝开关;
- 在卡1的stream提交卡1Tensor向卡2Tensor拷贝的任务;
- 在拷贝流中插入卡2的event事件;
- 在卡2的流中等待event事件;
- 从卡2中下载Tensor数据;
- 与原始数据做比对。
预期结果
- 数据比对与原始数据相同;
- 卡2event同步正确,在卡1stream中构造耗时操作,确保event能够等待拷贝动作结束。
量化拷贝验证
测试目的
- 量化Tensor拷贝需要调整内存布局,验证量化Tensor的拷贝结果正确。
测试步骤
- 构造随机的量化Tensor;
- 将量化Tensor上传到设备上;
- 使用aclrtmemcpy直接拷贝数据;
- 从设备上将Tensor下载下来;
- 与原始数据作对比。
预期结果
- 步骤3的memcpy的结果与原始数据不同,因为上传过程做了内存布局调整;
- 步骤5数据对比与原始数据相同。
4.2 算子单元测试
单元测试复用社区的单元测试用例(test-backend-ops),包含1500多个用例。其覆盖的场景有:
- 算子多shape多dtype验证,保证该算子所有的输出输出的shape和dtype类型都能够覆盖;
- 算子的精度验证,用例会构造随机数据,分别在设备上和CPU上运行,最后对比精度,两个Tensor的归一化方差需要小于 1e-6。
- 计算结果越界检查,由于推理过程中,Tensor是紧密排列,所以每个tensor的计算结果不能越界,否则会损坏其他tensor的数据,用例会在每个输入和输出tensor前后分别放置一个随机tensor,通过对比随机tensor的计算前后的结果,来检查是否存在越界行为。
单元测试用例会判断后端的算子支持情况,理论上,所有支持的算子(包括shape和dtype)都需要通过该测试用例集的验证。
4.3 性能测试
算子的性能测试用例与单元测试用例相同,区别是性能测试用例不会验证精度,也不会创建随机tensor用作越界检查。性能测试会构造一个特殊的图,包含最多8192个计算节点,然后交给后端进行推理,并计算平均每次的执行时间,以及数据吞吐率。
- 910B对于简单算子(包括直接调用aclnn接口的,或者做了简单的参数调整的)性能要超过Intel主流CPU的性能。
- 对于复杂算子(包括构造多个临时tensor,以及需要多个算子组合的)暂不做算子的性能要求。
- 非910B芯片,不做性能要求。
910B模型推理(llama3 8B)整体性能,token延迟需要小于100ms(人类的阅读速度大致是10个token/s,延迟小于100ms,可以满足人类的阅读需求),吞吐需要超过300token/s(0.6 * A100 vllm llama3 8B的推理性能)。
以下为 Qwen 2.5 全系列模型在昇腾 910B 上的推理性能表现汇总数据,包括 Qwen2.5 0.5B、1.5B、3B 的 Q8_0 和Q4_0 量化的推理性能数据作为对比参考:
| Model | Tokens / Second | NPU Util | NPU Mem | NPU Card(64G/Card) |
|---|---|---|---|---|
| Qwen2.5 0.5B FP16 | 42 tokens/second | Util 6~7% | Mem 7% | 单卡 |
| Qwen2.5 1.5B FP16 | 35 tokens/second | Util 11~13% | Mem 10% | 单卡 |
| Qwen2.5 3B FP16 | 29 tokens/second | Util 15~16% | Mem 15% | 单卡 |
| Qwen2.5 7B FP16 | 32 tokens/second | Util 16~21% | Mem 16% | 单卡 |
| Qwen2.5 14B FP16 | 19 tokens/second | Util 19~22% | Mem 28% | 单卡 |
| Qwen2.5 32B FP16 | 10.5 tokens/second | Util 10~45% | Mem 54% | 双卡 |
| Qwen2.5 72B FP16 | 6 tokens/second | Util 10~60% | Mem 78% | 三卡 |
| Qwen2.5 0.5B Q8_0 | 6.5 tokens/second | Util 2~5% | Mem 6% | 单卡 |
| Qwen2.5 0.5B Q4_0 | 6 tokens/second | Util 4~5% | Mem 6% | 单卡 |
| Qwen2.5 1.5B Q8_0 | 3.5 tokens/second | Util 4~11% | Mem 8% | 单卡 |
| Qwen2.5 1.5B Q4_0 | 17~18 tokens/second | Util 9~12% | Mem 7% | 单卡 |
| Qwen2.5 3B Q8_0 | 3.2 tokens/second | Util 10~15% | Mem 10% | 单卡 |
| Qwen2.5 3B Q4_0 | 14.5 tokens/second | Util 8~15% | Mem 8% | 单卡 |
对其中的 Qwen 2.5 0.5B FP16 模型进行并发测试的性能表现如下:
| Concurrency | Tokens / Second | Throughput | NPU Util | NPU Mem |
|---|---|---|---|---|
| 1 | 39 tokens/second | 39 | Util 6~7% | Mem 7% |
| 2 | 38 tokens/second | 76 | Util 6~7% | Mem 7% |
| 3 | 37.66 tokens/second | 113 | Util 6~7% | Mem 7% |
| 4 | 34.25 tokens/second | 137 | Util 6~7% | Mem 7% |
| 5 | 31 tokens/second | 155 | Util 6~7% | Mem 7% |
| 6 | 28.16 tokens/second | 169 | Util 6~7% | Mem 7% |
| 7 | 27.57 tokens/second | 193 | Util 6~7% | Mem 7% |
| 8 | 26.87 tokens/second | 215 | Util 6~7% | Mem 7% |
| 9 | 26 tokens/second | 234 | Util 6~7% | Mem 7% |
| 10 | 26.9 tokens/second | 269 | Util 6~7% | Mem 7% |
| 20 | 20.3 tokens/second | 406 | Util 6~7% | Mem 8% |
| 50 | 10.34 tokens/second | 517 | Util 3~5% | Mem 8% |
| 100 | 4.17 tokens/second | 417 | Util 2~5% | Mem 9% |
4.4 模型精度验证
除了算子的精度验证以外,对模型需要做整体的精度验证,以避免在数据加载拷贝,kv_cache操作等过程中出现错误。
eval-callback
llama.cpp社区提供了一个精度对比工具:eval-callback,这个工具会执行一次推理过程,并将推理过程中所有涉及的算子的计算结果进行打印。通过对比相同seed情况下的NPU和CPU的推理结果,判断整个推理过程是否存在异常。
需要注意的是,tensor的内容在会存在微小的差异,这不属于精度异常。
CPU推理对比
使用llama3模型,使用相同的seed,分别在NPU和CPU上进行相同的推理内容,理论上前数百token应该完全一致。由于存在精度的微小差异,推理累计的过程中,在长回复的后段,可能会出现细微差异。
4.5 模型支持验证
目前,llama.cpp支持以下模型以及多种量化格式,我们仅关注fp16,Q8_0和Q4_0三种dtype。
模型支持的原则是不存在不支持的算子,检查方式是查看切图的情况,如果出现了大量子图(超过100),说明存在算子不支持,已经fallback到CPU进行推理,此类模型虽然能够完成推理,但是推理性能较低。
| 模型 | FP16 | Q8_0 | Q4_0 |
|---|---|---|---|
| AquilaChat2-7B | √ | √ | √ |
| Baichuan-7b | √ | √ | √ |
| Baichuan2-7B-Chat | √ | √ | √ |
| bitnet_b1_58-large | √ | √ | √ |
| bloom-560m | √ | x | √ |
| bloomz-alpaca-560m | √ | x | √ |
| c4ai-command-r-35B-v01 | x | x | x |
| chatglm3-6B | x | x | x |
| chinese-alpaca-2-1.3b | √ | √ | √ |
| CodeShell-7B | √ | √ | √ |
| deepseek-ai_deepseek-coder-1.3B-base | x | x | x |
| deepseek-ai_DeepSeek-V2-Lite | x | x | x |
| deepseek-coder-6.7B-instruct | x | x | x |
| DeepSeek-V2-Lite-64x1.5B | x | x | x |
| falcon-7b-instruct | √ | √ | √ |
| flan-t5-large | √ | √ | √ |
| gemma-2-9b-it | √ | √ | √ |
| glm-4-9B | x | x | x |
| gpt2 | √ | √ | √ |
| Gpt2-163M | √ | √ | √ |
| granite-3B-code-instruct | √ | √ | √ |
| GritLM-7B | √ | √ | √ |
| internlm2_5-7b-chat | √ | √ | √ |
| koala-7B-HF | √ | √ | √ |
| Llama-2-7b-chat-hf | √ | √ | √ |
| Llama-3-Smaug-8B | √ | √ | √ |
| Llama2-Chinese-7b-Chat | √ | √ | √ |
| Llama3-8B | √ | √ | √ |
| Llama3-8b-chinese | √ | √ | √ |
| mamba-130m-hf | √ | √ | √ |
| Mistral-7B-Instruct-v0.2 | √ | √ | √ |
| Mixtral-8x7B-Instruct-v0.1 | X | √ | √ |
| mpt-7B | √ | √ | √ |
| OLMo-1B-hf | √ | √ | √ |
| OpenELM-3B-Instruct | √ | √ | √ |
| Orion-14b-base | √ | √ | √ |
| phi1 | x | x | x |
| phi2 | x | x | x |
| Phi-3-mini-4k-instruct | √ | √ | √ |
| plamo-13b | √ | √ | √ |
| pythia-70M | x | x | x |
| Qwen-7B | √ | √ | √ |
| Qwen2-1.5B-Instruct | √ | x | √ |
| Refact-1_6B-fim | √ | √ | √ |
| SmolLM-135M | √ | √ | √ |
| stablelm-zephyr | x | x | x |
| stablelm-2-zephyr-1_6b | x | x | x |
| starcoderbase-1b | √ | √ | √ |
| starcoder2-3b | √ | √ | √ |
| vigogne-7b-chat | √ | √ | √ |
| xverse-7b-chat | √ | √ | √ |
| Yi-6b-Chat | √ | √ | √ |
4.6 社区CI
目前由于资源限制,暂时无法向社区提供开发机和CI机器,但是需要保证编译通过,防止社区的重构导致的昇腾后端被破坏的问题。编译不需要昇腾硬件,可以使用社区的CI机器。
- 提供昇腾构建的容器镜像,避免配置复杂的环境。
- 提供github workflow的job,添加昇腾的CI验证,并作为门禁。
5. Ollama支持
Ollama 是一个旨在提升本地大型语言模型(LLM)运行效率和灵活性的开源平台,快速在本地部署启动大模型的应用。Ollama 的设计初衷是通过优化硬件加速和支持更高效的推理计算,帮助开发者和研究人员更方便地在本地部署和运行 LLM,从而不依赖云计算资源或其他昂贵的基础设施。,Ollama使用llama.cpp作为推理引擎。一条命令可以完成安装和模型拉起。
安装
1 | curl -fsSL https://ollama.com/install.sh | sh |
运行
1 | ollama run llama3 |
除此之外,Ollama还有有一个模型的仓库,保存有海量的gguf模型,其兼容openAI API,有着众多的前端应用。
为了能够充分的利用llama.cpp的昇腾后端能力,简化昇腾使用门槛,同时需要完成Ollama的昇腾适配。简单来说,OIlama需要适配一下几个关键部分:
构建
Ollama会构建llama.cpp工程,并将二进制打包到ollama的二进制文件中,在构建ollama的过程中,需要完成llama.cpp的昇腾版本的构建。
NPU检测
Ollama在运行时会检测NPU硬件,显存容量等,来判断模型是否能够运行,以及合理的模型拆分方式,所以需要在ollama中实现必要的昇腾硬件检测接口。
拉起
Ollama运行模型时,会拉起对应后端的llama.cpp服务器,这里需要根据硬件检测的结果来拉起NPU版本的llama.cpp服务器。
这里仅做Ollama兼容昇腾后端的简单洞察,不做详细设计,社区方案已完成,PR提交中。
6. 社区跟进
llama.cpp是一个非常活跃的社区,平均每天有十几个提交的合入,包括大量的重构和大粒度特性的合入。昇腾后端需要紧跟社区的发展路线,根据社区的重构和特性进行适配。
同时,在社区也存在对昇腾后端的需求,以及问题反馈,需要及时完成解决。
社区没有要求SLA,原则上,简单问题修复和重构适配应当在5个工作日内完成,特性需求根据实际情况灵活处理。
7. 文档和说明
为了帮助llama.cpp的昇腾用户,需要编写详尽的文档,包括环境搭建,构建,运行,模型和数据类型支持情况以及贡献指导等。
7.1 社区doc
- 在社区README添加Ascend的支持描述,并且提供跳转链接。
- 提供环境搭建步骤,包括操作系统版本,昇腾驱动和CANN的版本要求和安装方法。
- 提供Dockerfile,包含llama.cpp所需的环境配置,能够避免复杂的环境部署。
- 提供构建,运行的命令。
- 提供模型和数据类型支持情况。
- 提供issue和PR提交规范。
7.2 昇腾开源手册
为了方便中文用户,以及昇腾社区入口的用户,还需要在昇腾开源文档中提供中文版的step by step构建和推理手册。
| PR | 代码量 |
|---|---|
| [CANN] Add Ascend NPU backend #6035 | +10,756 −8 |
| [CANN] Add doc and docker image #8867 | +329 −0 |
其他参与review的PR和issue见链接。
8. 项目引用
ollama
Ollama是一款专注于在本地运行大型语言模型的工具,旨在简化模型的部署和使用,提供高性能且无需云端依赖的AI推理体验,使用llama.cpp作为推理引擎,以git submodule的方式引用llama.cpp代码。目前已与2012同事一同完成设计并提交PR。
llama edge
Llama Edge是一个为边缘设备优化的轻量级大语言模型框架,旨在支持本地化、高效的推理,以满足低延迟和有限资源的计算需求,使用llama.cpp作为其推理后端。llama edge官方发表了一篇知乎的回复以及一篇官方文档。
llamabox&gpu stack
Llamabox是一个便捷的平台,提供开箱即用的大语言模型部署方案,使用户能够轻松运行和管理AI模型;而gpustack是一项云服务,专为高性能计算和AI模型训练优化,提供灵活的GPU资源共享和管理功能,其使用了llama.cpp作为其推理后端之一。有一篇使用gpustack使用昇腾推理的实践文章。