Triton 对 PyTorch的重要性
为什么需要编译
相比于Eager模式,编译有以下优势:
优化性能:通过全局优化,减少算子之间的数据拷贝来提升执行速度。
降低延迟:提前优化代码逻辑,减少运行时解释开销,适用于实时应用。
复杂优化策略:实现操作融合、并行执行等高级优化。
更快的算法支持:不需要实现对应的各种融合算法,完成lower和pass即可适配。
静态分析与错误检查:提前捕捉潜在错误,提高代码质量。
所以编译模式是一定要支持的技术路线。
为什么PyTorch编译需要Triton
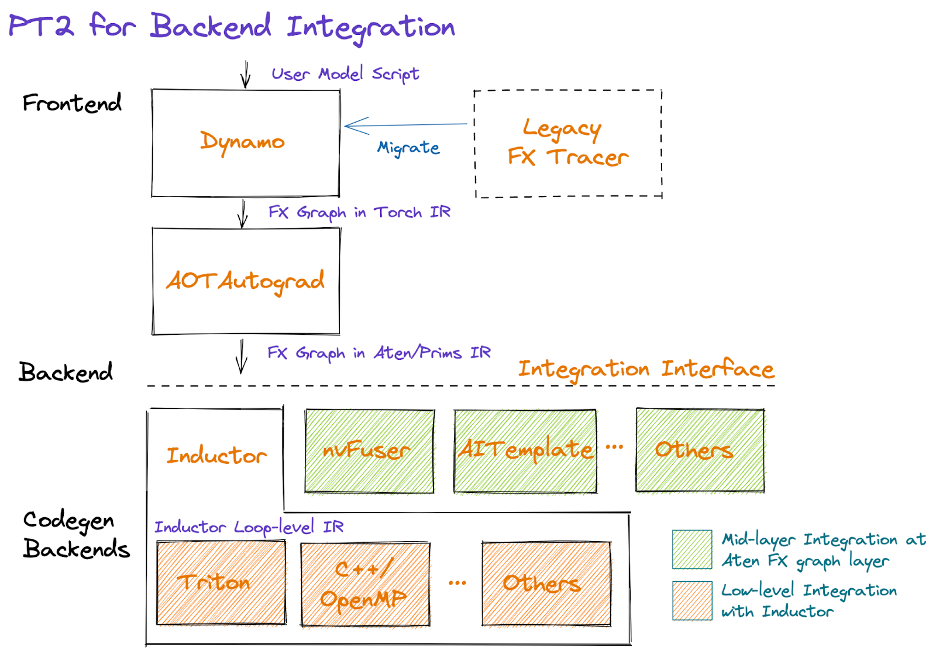
为什么选择Inductor
PyTorch有多个后端编译器,都可以从FX Graph进行模型编译。Intree的有cudagraph,onnxrt,openxla,tvm以及inductor,out of tree的有nvFuser和AITemplate等。Inductor相较于其他编译器,有以下优势,并逐渐成为PyTorch主力发展的编译器。
动态编译:能够根据输入数据的特性在运行时生成优化代码,实现最佳性能。
实时优化:允许在推理过程中对计算图进行修改和优化,无需重新编译整个模型。
支持复杂操作:处理多种复杂操作和动态控制流,增强模型的表达能力。
集成现有 API:与 PyTorch API 无缝集成,降低学习曲线,方便开发者使用。
硬件适配:根据不同硬件生成特定优化代码,充分利用计算能力,目前支持CPU和GPU。
配置选项:提供多种参数和选项,允许用户自定义优化策略,增强灵活性。
性能调优:在运行时监控性能,根据实际情况自动选择最优执行路径。
Inductor会做很多通用优化,使得使用Inductor IR的后端均可以享受到这些优化的能力。
- Integrating a new backend at the AtenIR/PrimsIR level is straightforward and provides more freedom to the new backend to optimize the captured graph. But it might be suboptimal performance if the backend lacks the DL compiler capability because the decomposed operations for a single operation might need more memory and worse data locality compared with the single operation if the decomposed operations can't be fused.
- Integrating at the Inductor loop IR level can significantly simplify the complexity of design and implementation by leveraging the Inductor's fusion capability and other optimizations directly. The new backend just needs to focus on how to generate optimal code for a particular device.
为什么选择Triton
Inductor目前支持三个后端:OpenMP,Halide以及Trition
Triton 是一种用于并行编程的语言和编译器。它的目标是提供一个基于 Python 的编程环境,以便高效地编写自定义的深度神经网络(DNN)计算核心,这些核心能够在现代 GPU 硬件上以最大吞吐量运行。
AI算子编写2个最关键的点:
- 编写的复杂程度;
- 算子执行的效率。
Triton的目标是使用简单的实现方法(类似Python语言),让绝大部分的开发者能够开发出媲美CUDA专家编写出的算子执行效率。
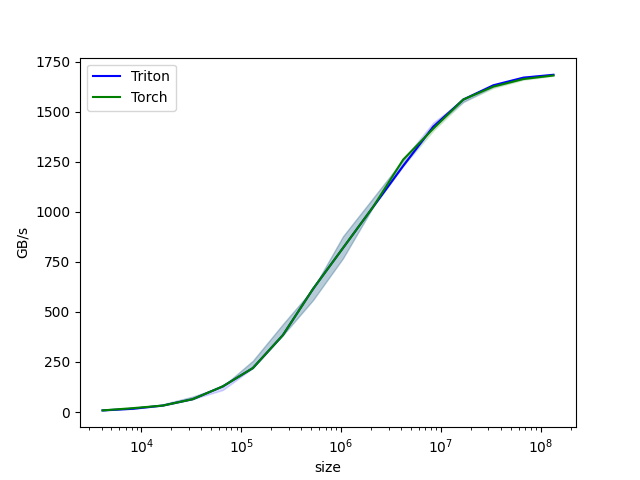
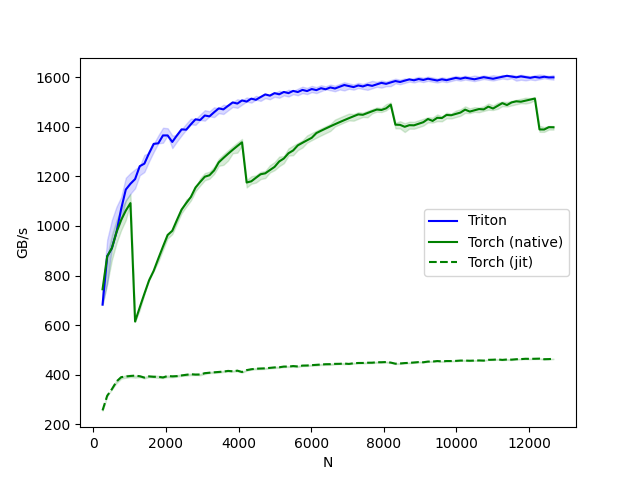
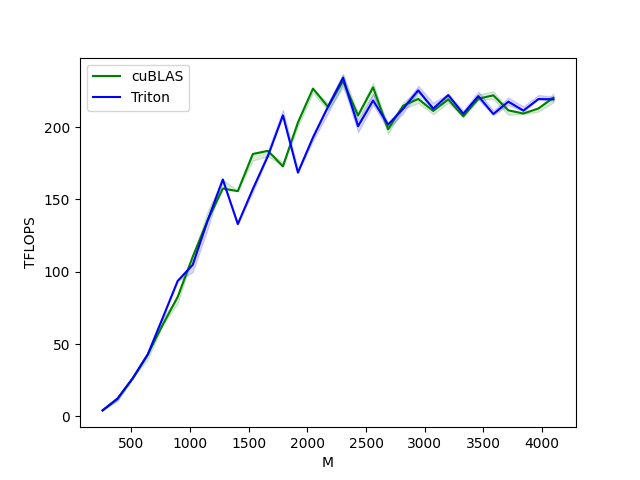
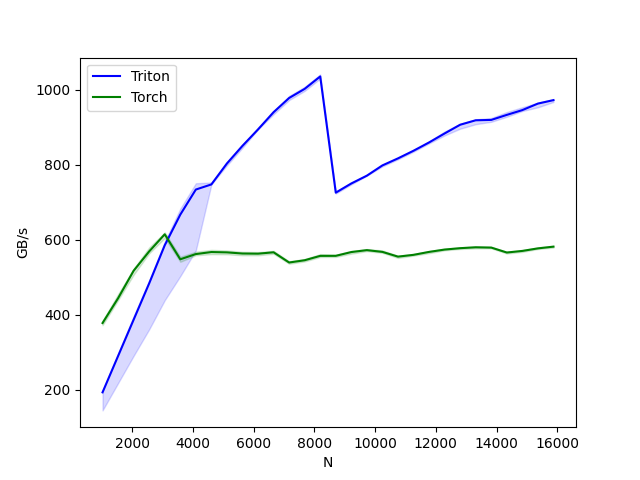
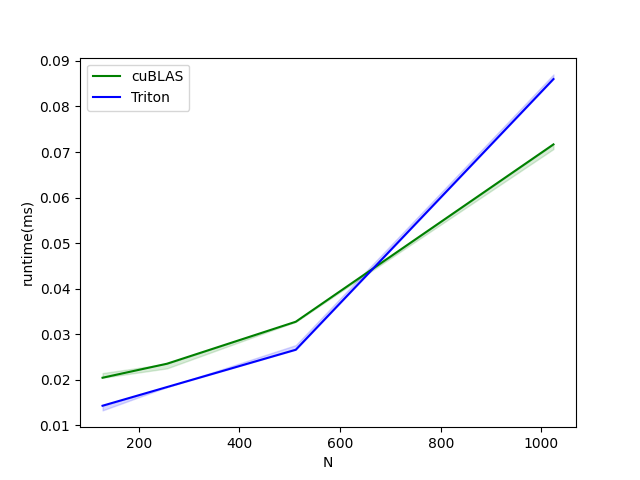
上图可以看出,使用简单的算子实现可以与cuBLAS以及Torch aten算子相同甚至更高的执行效率。
除此之外,FlagGems算子库,unsloth微调框架也基于Triton编写算子,并且字节等互联网公司也在使用Triton来高效的编写后端无关的高性能算子。
Triton架构
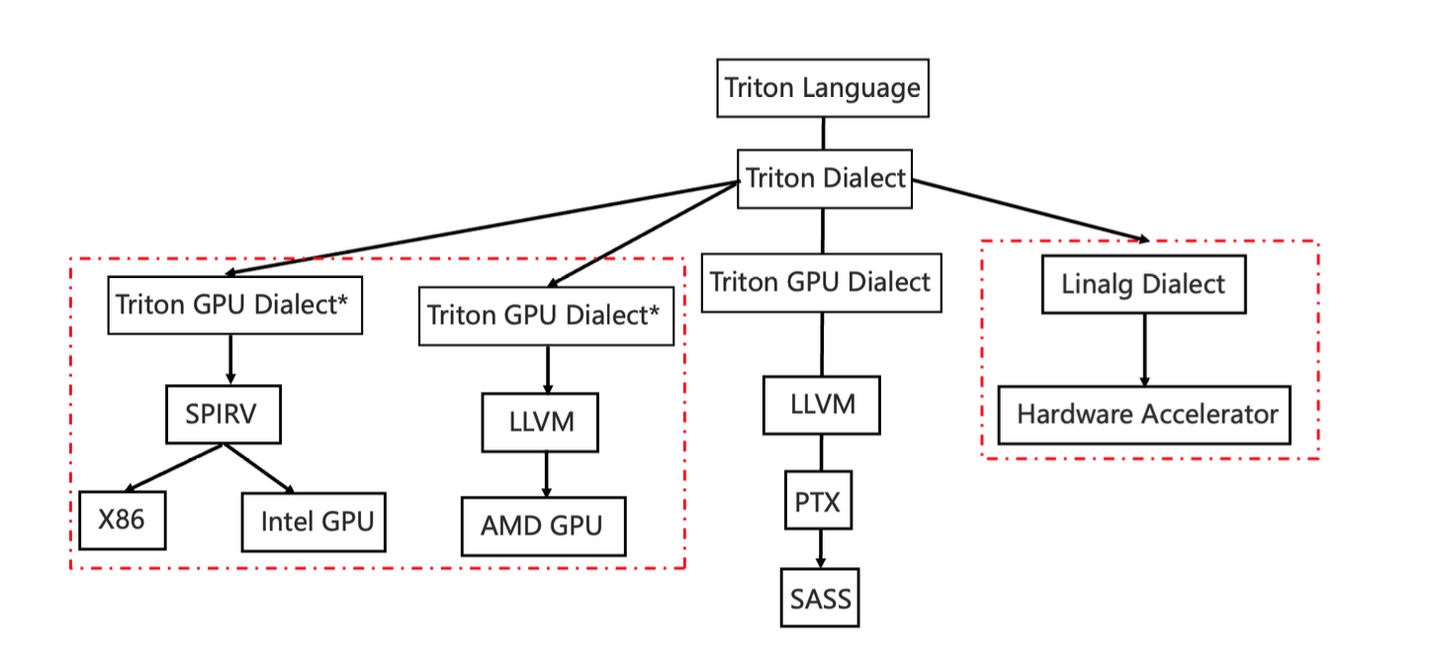
1 | Nvidia GPU: TritonDSL -------------> ttir -> ttgir -> ptx -> cubin |
Triton的工作原理就是将TritonDSL一步步转换成适合于硬件执行的二进制的过程。
- Triton利用llvm的MLIR框架,注册TritonIR以及TritonGpuIR,以及相应的pass和convert;
- 首先Triton会将代码用ast.parse解析,将ast语法书转换成ttir;
- 使用注册的pass和convert函数,对ttir进行优化并转换成ttgir;
- 继续用pass和convert函数,对ttgir转换成llvm ir;
- 使用nvidia提供的工具将llvm ir转换成ptx文件;
- 使用nvidia提供的工具将ptx文件编译成二进制cubin。
洞察启示
- Triton是昇腾支持Torch.compile的必经之路;
- Triton的支持对昇腾的三方库原生支持有很大的帮助;
- 借助triton-share的能力,可以进一步将ttir转换成linalg IR,后者对昇腾亲和,减少适配工作量;