推理全场景洞察
推理场景
计算机视觉:图像分类,目标检测,人脸识别,图像生成。
自然语言处理(NLP):翻译,语音识别,文本分类,内容审核。
自动驾驶
生物学:医学影响分析,基因分析,蛋白质预测。
金融:信用,风控。
制造业:质量控制,成本控制。
零售业:推荐广告系统,库存管理。
能源:智能电网。
大模型推理:LLM,多模态模型推理。
推理的一般流程
以目标检测为例:
预训练模型获取:从 Huggingface或者其他预训练模型平台上下载模型;
模型转换:根据使用的推理框架,将下载的模型转换成对应的格式;
数据预处理:视频解码,并从流中抓取图像,将图像进行裁剪,旋转,翻转,调整色彩空间,标准化等操作;
模型推理:将处理完成的图像数据输入模型进行推理,得到推理结果;
后处理:将模型推理结果进行处理,获取目标框,标签等信息;
结果展示:将原始图像和推理结果进行融合,给检测的目标加上框和目标类型标签。
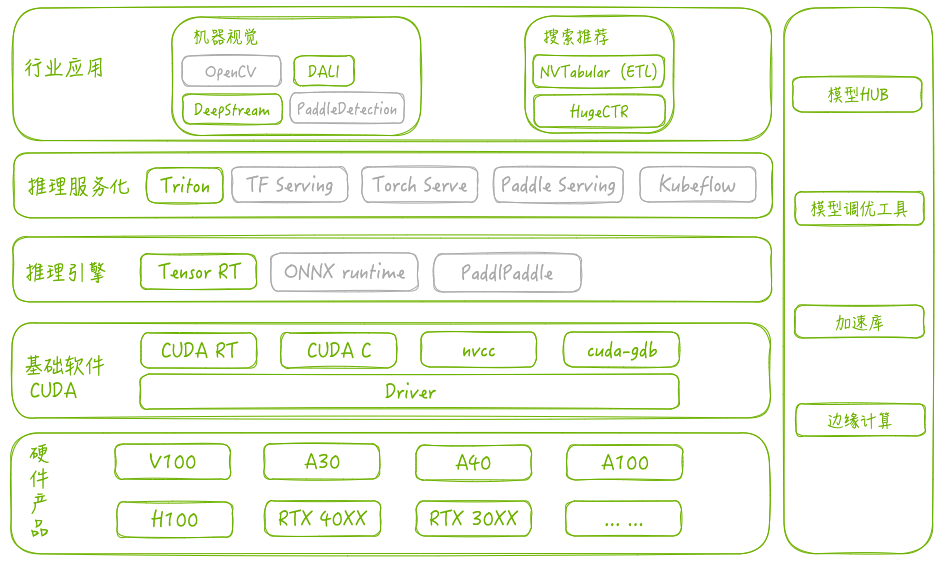
推理技术栈
Nvidia
昇腾
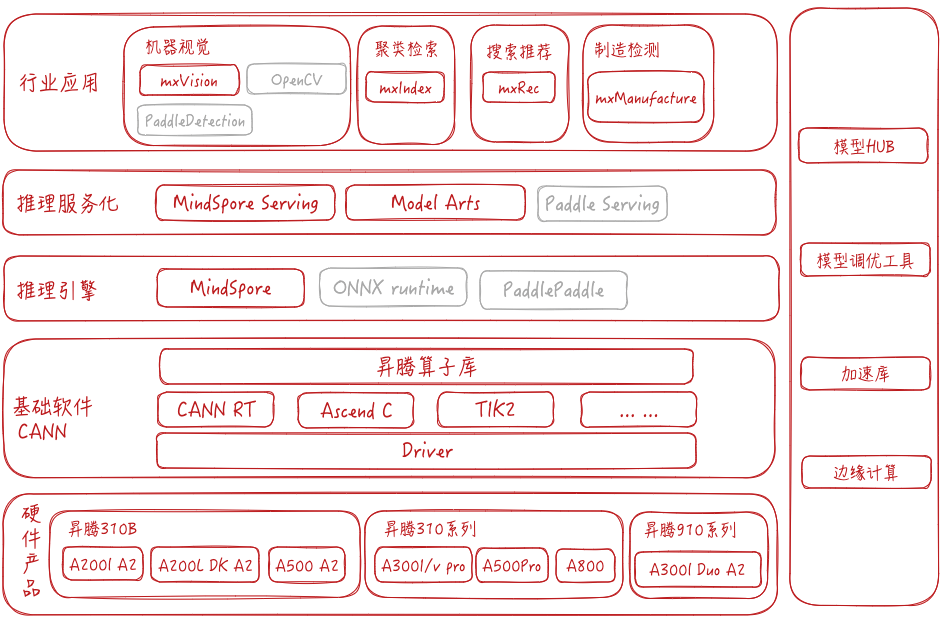
推理技术栈自下而上一般为:
- 硬件:参与推理的硬件,例如CPU,GPU和NPU等,Nvidia目前常用的GPU为Volta->Turing->Ampere->Hopper等架构,Ascend为310系列和910系列芯片, 采用Davinci架构。
- 驱动和基础软件:此类软件包括加速卡的驱动程序,异构计算运行时(CUDA RT, CANN RT),kernel开发调试工具等。除此之外,Ascend还提供了常用算子库。
- 推理引擎:推理引擎一般提供模型转换,模型优化,以及模型推理功能,并且提供运行的性能指标供性能分析和自动负载均衡。 大部分推理引擎都原生支持CUDA,对昇腾的原生支持较弱。
- 推理服务化:推理服务化工具一般提供restful和rpc接口,模型服务化部署。另外可以配合容器技术,调度技术和负载均衡等实现自动扩缩容,提高推理速度,提高资源利用率。基本上大多深度学习框架均提供了服务化部署能力,其中Triton支持多种后端,并提供了友好的接入接口。
- 行业应用:针对特定行业的预处理,pipeline或者相关的SDK用于简化行业应用的开发复杂度,甚至通过配置可以直接在行业内应用。
- 其他配套:其他配套例如预训练模型的仓库,模型调优工具,算法加速库以及边缘计算平台等。
推理流程中涉及的软件
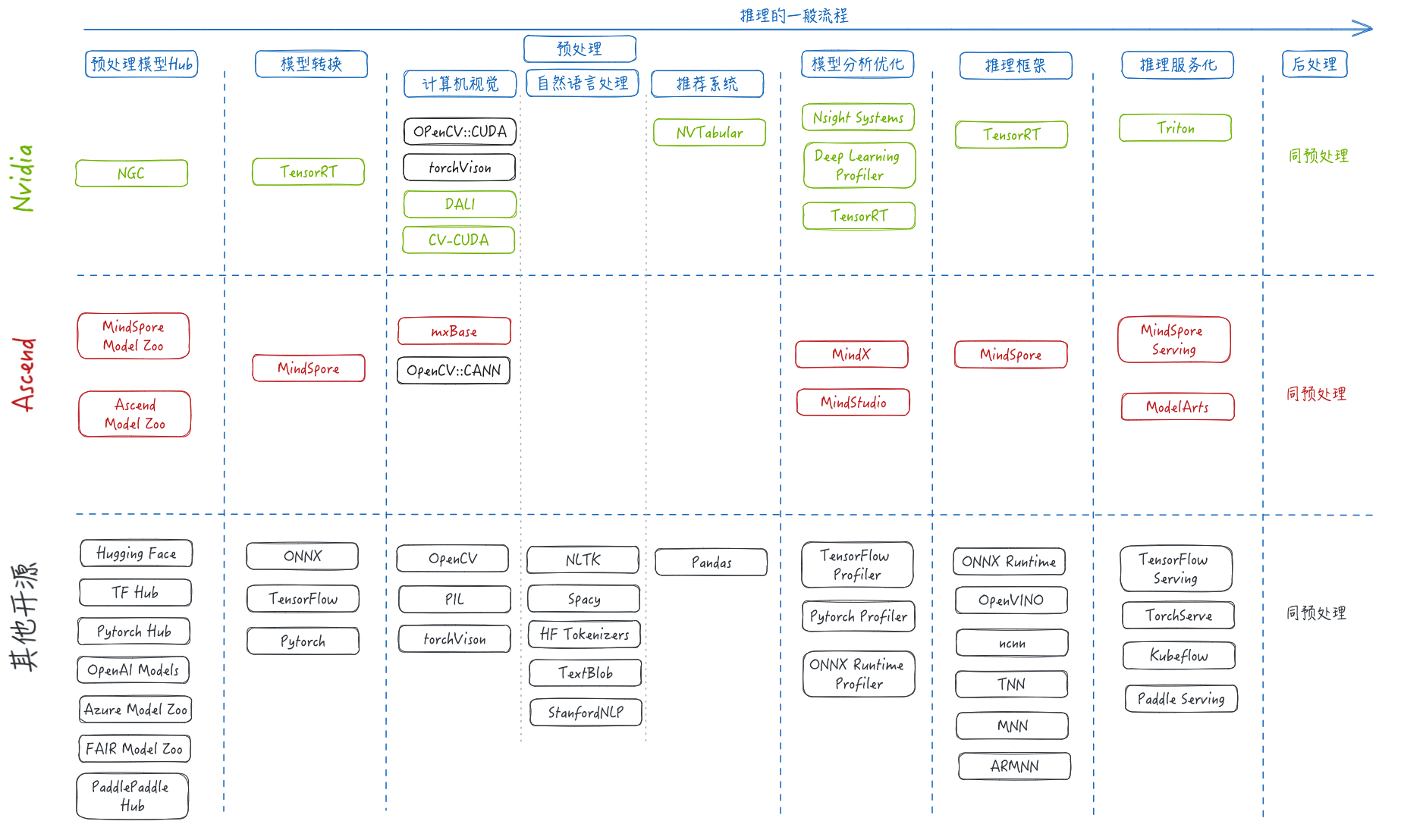
- 模型预处理hub:hub不仅能够保存预训练模型,并且能够通过代码api的方式直接下载并加载模型。昇腾的Model Zoo需要手动下载模型,Huggingface的预训练模型可以通过python api下载和使用。
- 模型转换:ONNX是一种开发的模型格式,可以与常见的深度学习框架进行转换。除此之外,其他的框架一般提供有限的模型转换能力,大多是同一个框架内的不同模型格式的转换。
- 预处理:计算机视觉中,Nvidia自研了部分适配GPU的加速库,并且常见的OpenCV,torchvision也原生支持GPU。目前对昇腾的支持较弱,目前仅有mxBase和OpenCV实现了少量的常用接口。昇腾推理的CV预处理,还需要依赖CPU处理。自然语言处理库由于算法的特殊性,无法充分利用并行计算能力,上述库基本上都仅在CPU上运行。Nvidia提供了推荐系统大量数据并能处理能力的库NVTabular,昇腾在此方面可以使用mxRec提供的加速能力。
- 模型分析优化:推理框架一般分为优化和运行两部分,其中优化部分对传入的模型根据底层架构进行优化。并且在执行过程中可以通过组件监控模型的运行情况,以用来模型调优,或者提供弹性扩缩容能力。
- 推理框架:推理框架是推理业务的重点,不同的推理框架能力各有优劣:
- TensorRT (TensorRT by NVIDIA):
- 优点:
- 面向 NVIDIA GPU 的深度学习推理优化库。
- 针对高性能、低延迟的推理任务进行了优化。
- 缺点:
- 仅适用于 NVIDIA GPU,不具备跨平台性。
- 优点:
- ONNX Runtime:
- 优点:
- 开放的模型表示格式,允许在不同框架之间共享和部署模型。
- 支持多种深度学习框架,如TensorFlow、PyTorch、Caffe等。
- 缺点:
- 部分框架的支持可能不如原生框架的性能优越。
- 优点:
- OpenVINO
- 优点:
- 多平台支持,支持多深度学习框架。
- 针对各设备硬件进行优化,能在多种设备上高性能推理。
- 缺点:
- 大量优化针对Intel硬件,对其他硬件厂商的优化有限。
- 开源版本功能限制,有些特性需要商业版支持。
- 优点:
- ncnn, TNN, MNN,ARMNN
- 优点:
- 面向移动端和嵌入式CPU或GPU,轻量级,弱依赖。
- 支持多种模型类型,有模型转换能力。
- 缺点:
- 非嵌入式平台(ARMNN在非ARM平台)支持较弱。
- 优点:
- TensorRT (TensorRT by NVIDIA):
- 推理服务化:主流的深度学习框架基本上都提供了服务化能力,可以通过restful或者rpc接口进行模型推理。其中Triton设计更为灵活,能够方便的集成不同的后端,目前已经支持主流深度学习框架的推理服务。目前还没有支持昇腾推理框架,但是可以通过pytorch插件或者ONNX runtime进行推理。
- 后处理:后处理将图例结果进行加工处理,并展示推理结果,所需软件与预处理大致相同。
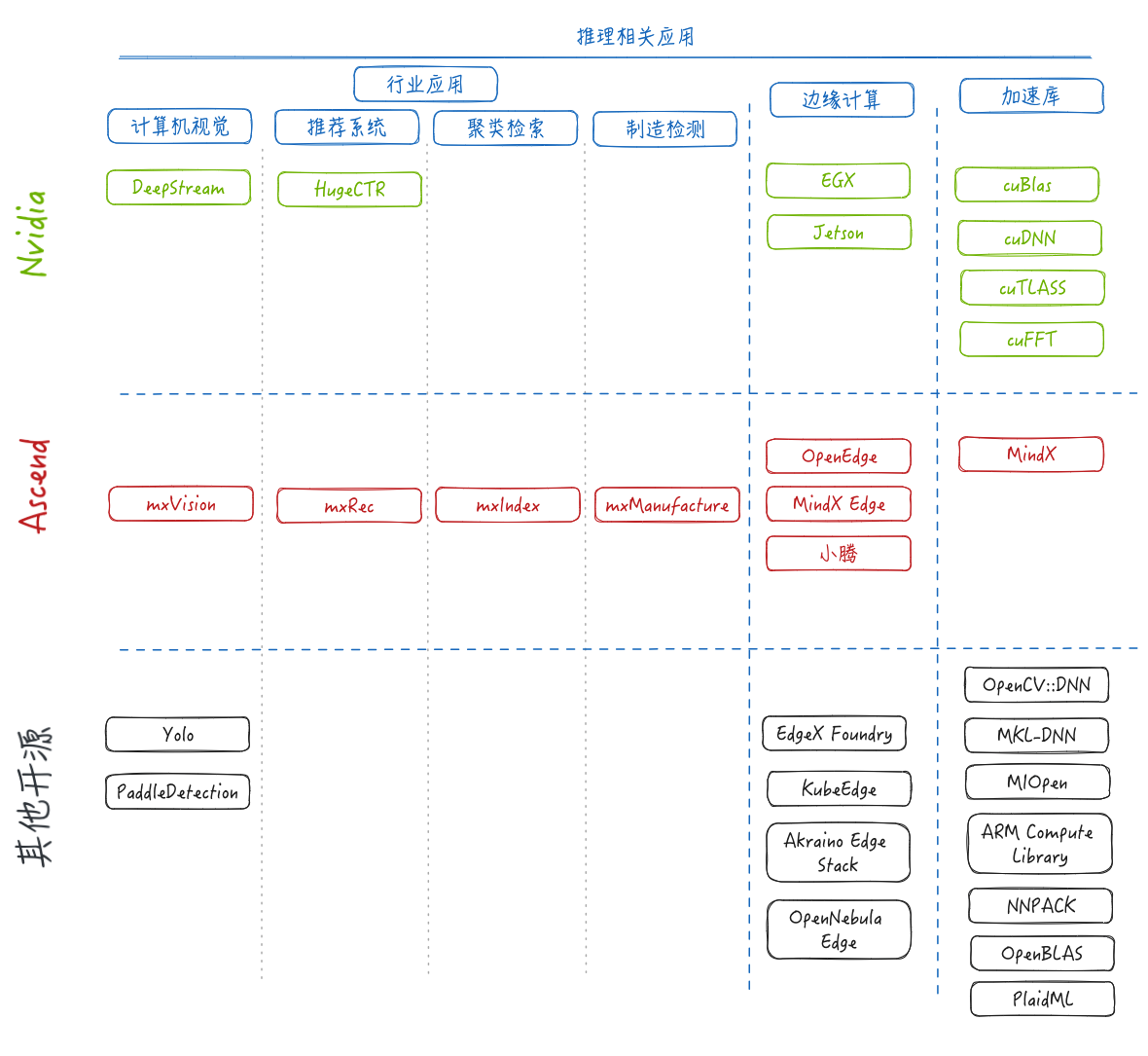
除了推理流程中的软件之外,还有行业应用,边缘计算,以及算法加速库。Nvidia和昇腾在这些领域均有涉及。
总结
- 昇腾在主流深度学习框架,推理框架以及推理服务化软件中,原生支持较弱,大部分框架在设计之初均考虑GPU支持,目前已经支持昇腾的框架多为后期开发。如果框架在后端支持上设计不够友好,接入难度较高。
- 计算机视觉预处理能力与GPU能力差距较大,包括OpenCV,torchvision等开源CV软件均原生支持GPU,并且Nvidia还有自研的图像预处理库,昇腾仅支持少量高频使用的接口,并且性能还存在差距。
- Nvidia和开源在框架,应用软件和加速库的使用上较为容易,社区活跃,文档完整规范,学习成本低。昇腾相关软件使用门槛较高,使用上相较而言较为繁琐。
- 建议在推理全流程中选择一个技术路线,做昇腾支持,在功能,性能上追平或超过友商,然后再考虑自研更适合昇腾场景的自研软件。