Pytorch DDP原理
DDP=分布式数据并行(DISTRIBUTED DATA PARALLEL),和DP一样也是一种数据并行的方法,详细文档可以参考官方手册
DDP使用
以下是使用NPU进行2个节点并行的示例代码。
1 | import os |
DDP原理
相关文件
| 文件 | 功能 |
|---|---|
| torch/nn/parallel/distributed.py | DistributedDataParallel类实现 |
| torch/csrc/distributed/c10d/reducer.cpp | DDP reduce类实现文件 |
| torch/csrc/distributed/c10d/reducer.hpp | DDP reduce接口文件 |
| torch/csrc/distributed/c10d/init.cpp | python C插件注册文件 |
进程交互
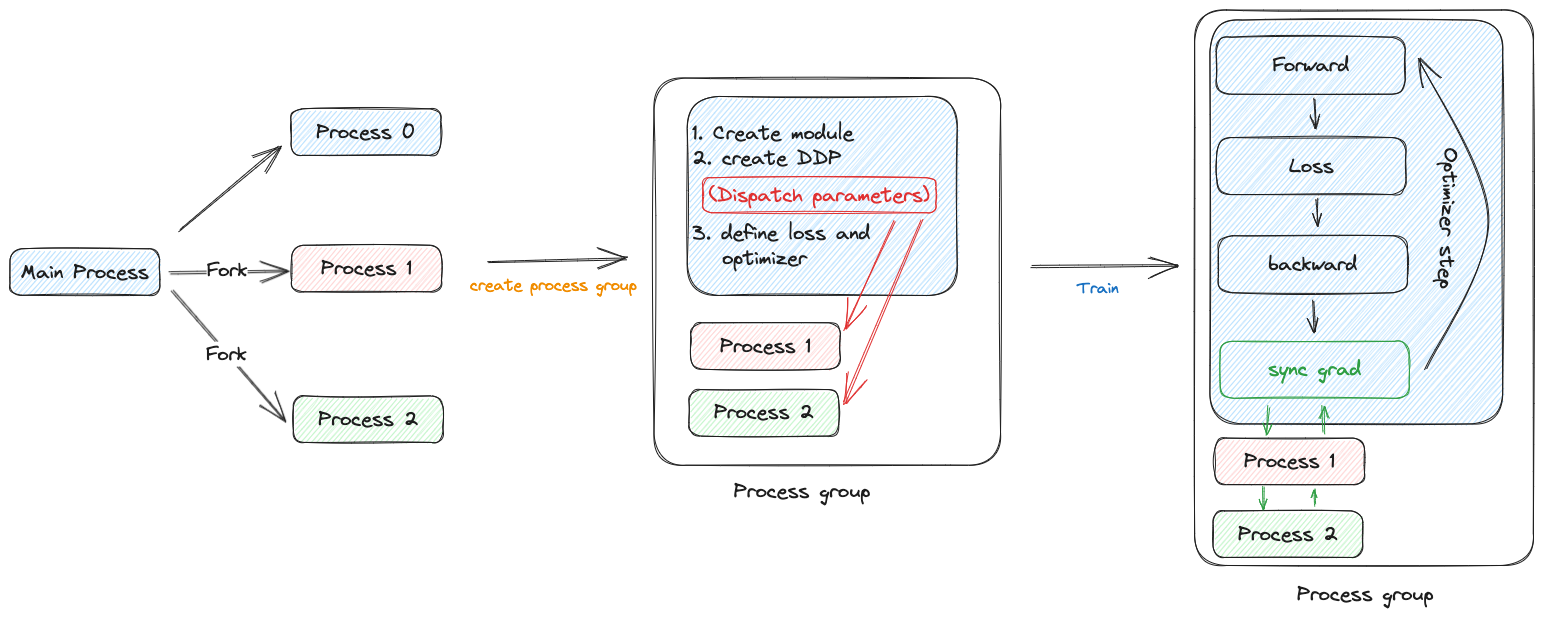
- 主线程通过torch.multiprocessing,fork出新的进程,满足word_size的要求,然后各个线程独立运行,主进程将自己的host和port放到环境变量中共子进程使用。
- 各个进程初始化process group,这些进程属于同一个进程组。
- 每个进程分别创建模型,DDP对象,定义loss函数和优化器。
- 创建DDP对象时,主进程会同步模型参数,这一步完成后,各个进程的模型一致。
- 每个模型输入部分数据,这些数据需要调用者自行分割,可以使用DistributedSampler。
- 然后执行模型的训练过程,每次backward执行完后,调用注册的reducer hook函数,做梯度聚合。
Reducer
普通模型的DDP,除了每次反向执行后的梯度同步之外,进程之间没有其他通信的需求。DDP构造时,会在每个模型参数上配置回调函数(autograd_hook),当参数的梯度计算完成后,会调用这个回调函数。为了能够一边计算,一边同步梯度数据,DDP将相邻参数分组,每个组叫一个bucket。
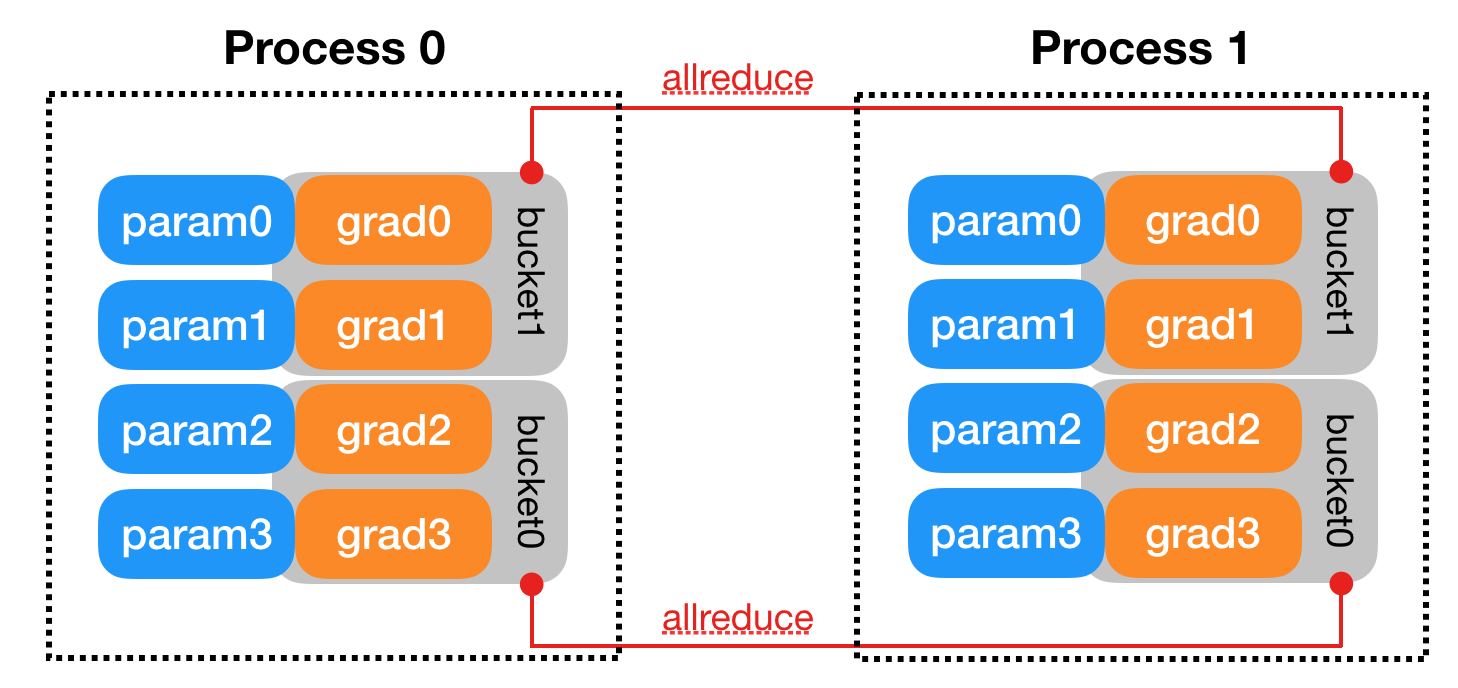
这是参数分组和allreduce的官方示意图,回调函数的执行流程如下:
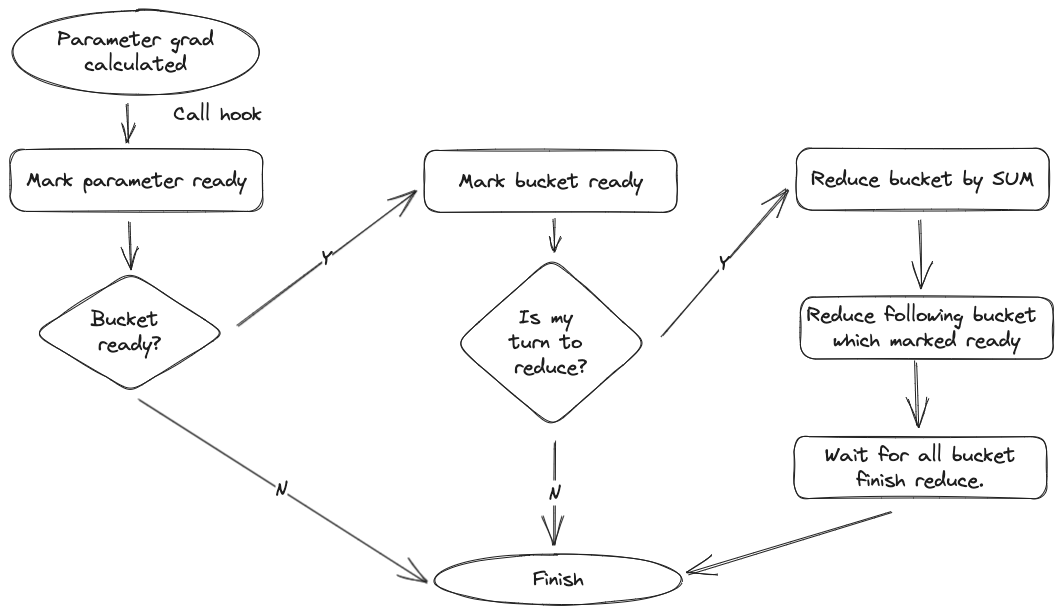
- 每个参数梯度计算完成后,均会调用回调函数,该回调函数会将参数标记为ready。
- 然后检查bucket中的pending是否为0,也就是bucket的参数是否全部完成梯度计算,如果完成,则准备进行一步all reduce。
- all reduce是一个异步方法,任务执行后不阻塞,继续执行。(如果某个进程的当前bucket没有执行完成,dist backend会等待,执行完成后异步返回)。
- 当所有的bucket都发起all reduce后,等待每个bucket的all reduce结果,所有结果都返回后,完成本次backward。