Pytorch DP原理
DP(DataParallel)=数据并行,DP框架会将数据切片,然后模型拷贝,并在不同的backend上并行执行。官方手册说明
DP使用
1 | model = LinearModel() |
从代码中看到,DP仅支持cuda,xpu或者昇腾,并不支持cpu。
DP原理
相关文件
| 文件 | 功能 |
|---|---|
| torch/nn/parallel/data_parallel.py | DP类实现 |
| torch/nn/parallel/_functions.py | DP中使用的自定义autograd Function |
| torch/nn/parallel/comm.py | 线程间数据传递接口,例如,gather,scatter等 |
| torch/nn/parallel/replicate.py | 模型拷贝相关 |
| torch/nn/parallel/parallel_apply.py | 多线程执行模型 |
| torch/nn/parallel/scatter_gather.py | scatter和gather的封装 |
| torch/csrc/cuda/python_comm.cpp | C语言实现的数据传递函数extension注册 |
| torch/csrc/cuda/comm.cpp | C语言的数据传递实现 |
基本原理
DP基于单机多卡,所有的卡都参与训练。相对于非数据并行训练来说,DP会将一个batch数据切分为更小的batch,将数据复制到每一张计算的卡上,然后复制模型到所有的卡上,进行多线程执行,Forward计算完成后,会在device[0]上收集到一组预测值。device[0]计算loss,然后执行Backward计算梯度。(计算Backward没有看到创建线程的过程,单线程执行??)
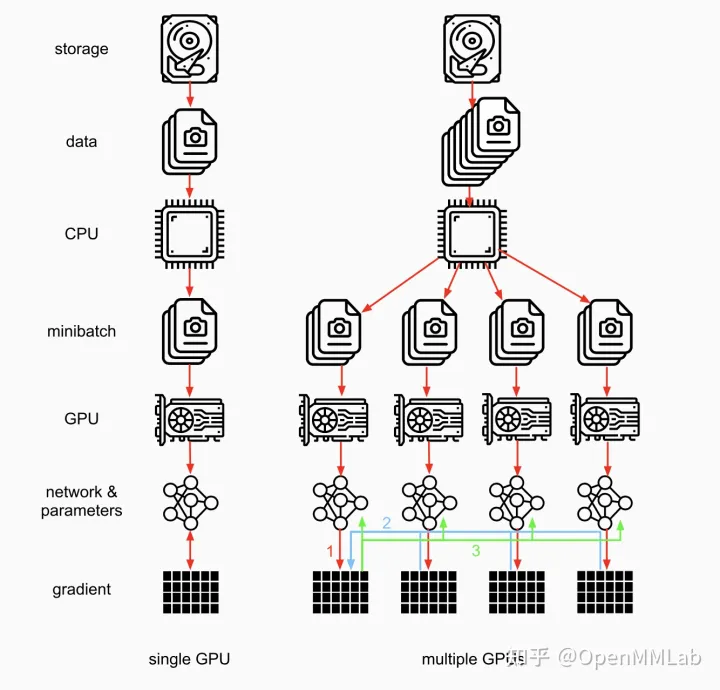
DP wapper
回顾DP使用方法,参与数据并行的模型进需要使用DataParalle包一层即可。
1 | model = torch.nn.DataParallel(model,device_ids=[0,1,2]) |
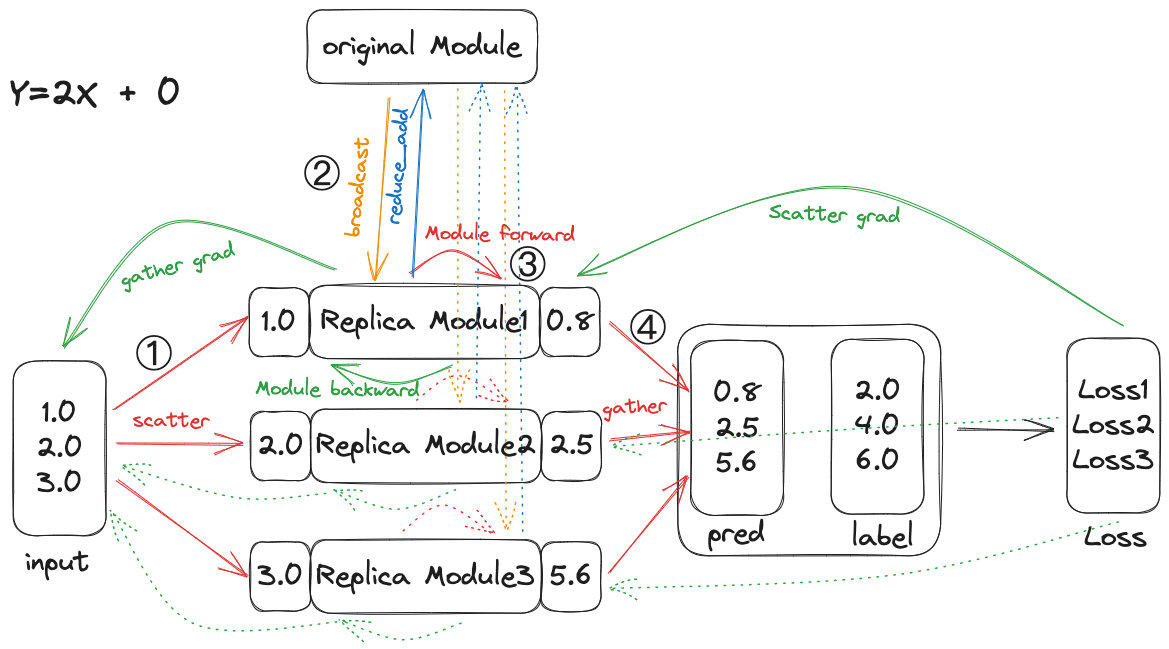
可以理解,下图就是上述代码的实现,DP就是在原本的模型执行之前增加了数据切分(Scatter),模型复制(Broadcast),然后将模型的并行执行结果进行合并(Gather)。
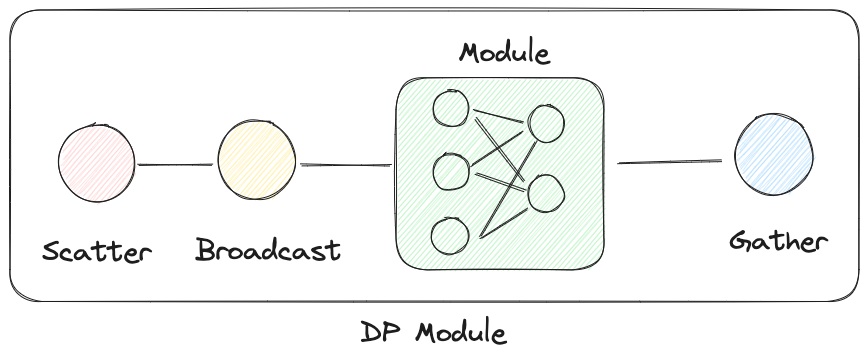
数据传递
DP的Forward函数核心代码如下:
1 | def forward(self, *inputs: Any, **kwargs: Any) -> Any: |
由于是单机单进程,所以数据的拷贝过程相对简单,以上述代码的scatter和broadcast为例,数据切分,然后将切分后的数据移动到指定设备上。但是Tensor还是在同一个数组中。
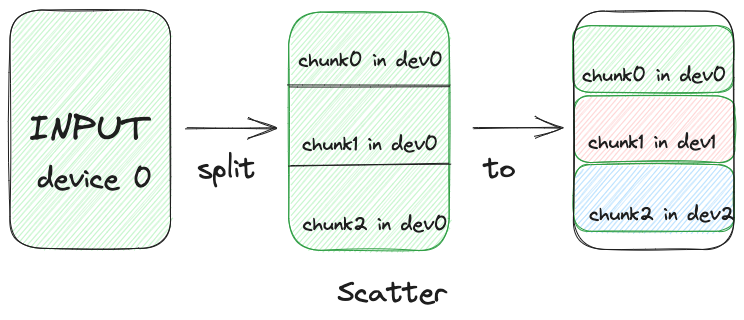
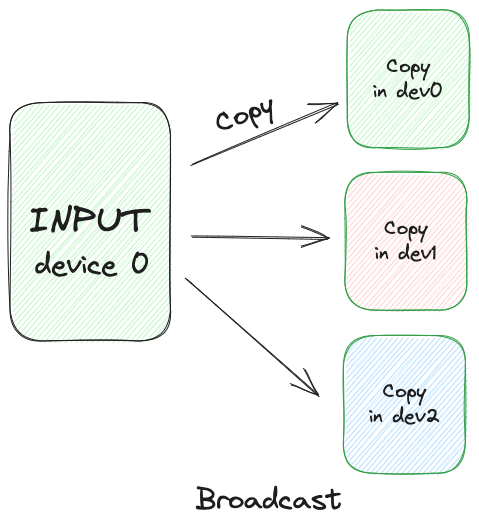
自定义自动梯度方法
Pytorch实现了自动梯度计算,除了官方实现的梯度计算之外,还能够自定义梯度计算方法,具体描述参考官方说明。以下是代码中对Function类的使用举例说明:
1 | Examples:: |
实现自定义自动梯度方法,需要继承Function类,并实现forward和backward方法,并且这两个方法均是静态的。使用自定义自动梯度方法的时候,不应该调用forward,而是调用Exp.apply,这样会返回forward的结果。相当于自己定义了算子的前向和后向的处理方法。当在执行反向传播的时候,会按反顺序调用自定义自动梯度方法的backward方法。
DP实现了三个自定义自动梯度方法,分别是Broadcast,Gather和Scatter,其反向传播方法内分别调用了Reduce_add,Scatter和Gather,即forward和backward中的动作是成对的。
训练流程
正向
- ①:将输入的一个batch切分成三个更小的batch
- ②:将模型的参数复制三份,分别发送到三个device上
- ③:启动三个线程,每个线程在不同的device上进行原始模型的前向计算
- ④:将三个线程的输出结果拼接到一起
Loss
- 在device[0]上计算Loss
反向
- ④:将Loss切分,分别发送给对应的模型
- ③:执行三个模型的backward方法,更新梯度(Backward Engine多线程处理)
- ②:将三个模型上的梯度相加,并储存到Original Module中(直接相加?)
- ①:将三个模型的梯度信息拼接到一起
官方建议
- 不建议使用DP来进行数据并行,因为这不是一个真正的并发执行(python GIL),并且,由于数据的转移,反而会减慢模型的执行,建议使用DDP。
- 所有拷贝来的数据都是一次性的,每次迭代后都会销毁重建,所以这些模型上如果有数据修改,将不会持久化。(Input最后做的gather是为了下一层网络的输入)