@cython.profile(False) cpdef inline check_hccl_status(HcclResult status): if status != HCCL_SUCCESS: raise HcclError(status)
defget_unique_id(): cdef HcclRootInfo root_info with nogil: status = HcclGetRootInfo(&root_info) check_hccl_status(status) ret = tuple([root_info.internal[i] for i inrange(HCCL_ROOT_INFO_BYTES)]) return ret
def__cinit__(self): self._comm = <HcclComm>0 def__dealloc__(self): if self._comm: with nogil: status = HcclCommDestroy(self._comm) check_hccl_status(status) self._comm = <HcclComm>0
def__init__(self, int ndev, tuple commId, int rank): cdef HcclRootInfo _root_info assertlen(commId) == HCCL_ROOT_INFO_BYTES for i inrange(HCCL_ROOT_INFO_BYTES): _root_info.internal[i] = commId[i] with nogil: status = HcclCommInitRootInfo(ndev, &_root_info, rank, &self._comm) check_hccl_status(status)
defsend(self, intptr_t sendbuf, size_t count, int datatype, int peer, intptr_t stream): with nogil: status = HcclSend(<void*>sendbuf, count, <HcclDataType>datatype, peer, self._comm, <aclrtStream>stream) check_hccl_status(status)
defrecv(self, intptr_t recvbuf, size_t count, int datatype, int peer, intptr_t stream): with nogil: status = HcclRecv(<void*>recvbuf, count, <HcclDataType>datatype, peer, self._comm, <aclrtStream>stream) check_hccl_status(status)
defwrite(self, value: Any, timeout: Optional[float] = None): # TODO: better organize the imports from ray.experimental.channel import ChannelContext
if self._inner_channel isnotNone: self._inner_channel.write(value, timeout) # 如果有内部channel,直接写到内部channel中。 return
# Otherwise no need to check timeout as the operation is non-blocking.
# Because both the reader and writer are in the same worker process, # we can directly store the data in the context instead of storing # it in the channel object. This removes the serialization overhead of `value`. ctx = ChannelContext.get_current().serialization_context ctx.set_data(self._channel_id, value, self._num_reads)
defread(self, timeout: Optional[float] = None) -> Any: # TODO: better organize the imports from ray.experimental.channel import ChannelContext
ctx = ChannelContext.get_current().serialization_context if ctx.has_data(self._channel_id): # No need to check timeout as the operation is non-blocking. return ctx.get_data(self._channel_id) # 如果缓存里有数据,从缓存读。
assert ( self._inner_channel isnotNone ), "Cannot read from the serialization context while inner channel is None." value = self._inner_channel.read(timeout) # 如果缓存里没有,就从内部channel中读,然后写到缓存供后续reader读取。 ctx.set_data(self._channel_id, value, self._num_reads) return ctx.get_data(self._channel_id)
defwrite(self, value: Any, timeout: Optional[float] = None): # No need to check timeout as the operation is non-blocking.
# Because both the reader and writer are in the same worker process, # we can directly store the data in the context instead of storing # it in the channel object. This removes the serialization overhead of `value`. ctx = ChannelContext.get_current().serialization_context ctx.set_data(self._channel_id, value, self._num_readers)
defread(self, timeout: Optional[float] = None, deserialize: bool = True) -> Any: assert deserialize, "Data passed from the actor to itself is never serialized" # No need to check timeout as the operation is non-blocking. ctx = ChannelContext.get_current().serialization_context return ctx.get_data(self._channel_id)
try: object_ref = worker.put_object( value, owner_address=None, _is_experimental_channel=True ) except ray.exceptions.ObjectStoreFullError: logger.info( "Put failed since the value was either too large or the " "store was full of pinned objects." ) raise return object_ref
# Find 1 reader in a remote node to create a reference that's # shared by all readers. When a new value is written to a reference, # it is sent to this reference. reader = readers[0] fn = reader.__ray_call__ self._node_id_to_reader_ref_info[node_id] = ReaderRefInfo( reader_ref=ray.get( fn.remote(_create_channel_ref, buffer_size_bytes) ), ref_owner_actor_id=reader._actor_id, num_reader_actors=len(readers), )
ifnotisinstance(value, SerializedObject): try: serialized_value = self._worker.get_serialization_context().serialize( value ) except TypeError as e: sio = io.StringIO() ray.util.inspect_serializability(value, print_file=sio) msg = ( "Could not serialize the put value " f"{repr(value)}:\n" f"{sio.getvalue()}" ) raise TypeError(msg) from e else: serialized_value = value
defwrite(self, value: Any, timeout: Optional[float] = None) -> None: """Write a value to a channel. If the next buffer is available, it returns immediately. If the next buffer is not read by downstream consumers, it blocks until a buffer is available to write. If a buffer is not available within timeout, it raises RayChannelTimeoutError. """ # A single channel is not supposed to read and write at the same time. assert self._next_read_index == 0 self._buffers[self._next_write_index].write(value, timeout) self._next_write_index += 1 self._next_write_index %= self._num_shm_buffers
defread(self, timeout: Optional[float] = None) -> Any: """Read a value from a channel. If the next buffer is available, it returns immediately. If the next buffer is not written by an upstream producer, it blocks until a buffer is available to read. If a buffer is not available within timeout, it raises RayChannelTimeoutError. """ # A single channel is not supposed to read and write at the same time. assert self._next_write_index == 0 output = self._buffers[self._next_read_index].read(timeout) self._next_read_index += 1 self._next_read_index %= self._num_shm_buffers return output
( remote_reader_and_node_list, local_reader_and_node_list, ) = utils.split_readers_by_locality(self._writer, self._reader_and_node_list) # There are some local readers which are the same worker process as the writer. # Create a local channel for the writer and the local readers. num_local_readers = len(local_reader_and_node_list) if num_local_readers > 0: # Use num_readers = 1 when creating the local channel, # because we have channel cache to support reading # from the same channel multiple times. local_channel = IntraProcessChannel(num_readers=1) self._channels.add(local_channel) actor_id = self._get_actor_id(self._writer) self._channel_dict[actor_id] = local_channel # There are some remote readers which are not the same Ray actor as the writer. # Create a shared memory channel for the writer and the remote readers. iflen(remote_reader_and_node_list) != 0: remote_channel = BufferedSharedMemoryChannel( self._writer, remote_reader_and_node_list, num_shm_buffers ) self._channels.add(remote_channel)
for reader, _ in remote_reader_and_node_list: actor_id = self._get_actor_id(reader) self._channel_dict[actor_id] = remote_channel
if self._meta_channel isNoneand self._writer_registered: # We are the writer. Therefore, we also need to allocate a metadata # channel that will be used to send the shape and dtype of the # tensor to the receiver(s). metadata_type = SharedMemoryType() self._meta_channel = metadata_type.create_channel( self._writer, self._reader_and_node_list, None, )
for tensor in tensors: assertisinstance( tensor, torch.Tensor ), f"{tensor} must be instance of torch.Tensor"
metadata = self._get_send_tensors_metadata(tensors) # 先发送元数据 if metadata isnotNone: self._meta_channel.write(metadata)
for tensor in tensors: # TODO: If there are multiple readers, can replace with a # broadcast. for rank in self._reader_ranks: self._nccl_group.send(tensor, rank) # 发送tensor数据
bufs: List["torch.Tensor"] = [] for meta in meta_list: buf = self._nccl_group.recv( meta.shape, meta.dtype, self._writer_rank, _torch_zeros_allocator # 在接收每个tensor ) bufs.append(buf) # TODO: Sync CUDA stream after receiving all tensors, instead of after # each tensor. return bufs
try: # Serialize the data. All tensors that match our current device # will be extracted into the serialization context and replaced # with a placeholder. cpu_data = self._worker.get_serialization_context().serialize(value) except TypeError as e: sio = io.StringIO() ray.util.inspect_serializability(value, print_file=sio) msg = ( "Could not serialize the put value " f"{repr(value)}:\n" f"{sio.getvalue()}" ) raise TypeError(msg) from e finally: # Pop the tensors that were found during serialization of `value`. gpu_tensors, _ = self.serialization_ctx.reset_out_of_band_tensors([]) # Reset the serialization method to now serialize torch.Tensors # normally. self.serialization_ctx.set_use_external_transport(False)
# First send the extracted tensors through a GPU-specific channel. self._gpu_data_channel.write(gpu_tensors) # Next send the non-tensor data through a CPU-specific channel. The # data contains placeholders for the extracted tensors. self._cpu_data_channel.write(cpu_data)
# Next, read and deserialize the non-tensor data. The registered custom # deserializer will replace the found tensor placeholders with # `tensors`. data = self._cpu_data_channel.read( timeout=timeout, ) # Check that all placeholders had a corresponding tensor. ( _, deserialized_tensor_placeholders, ) = self.serialization_ctx.reset_out_of_band_tensors([]) assert deserialized_tensor_placeholders == set(range(len(tensors)))
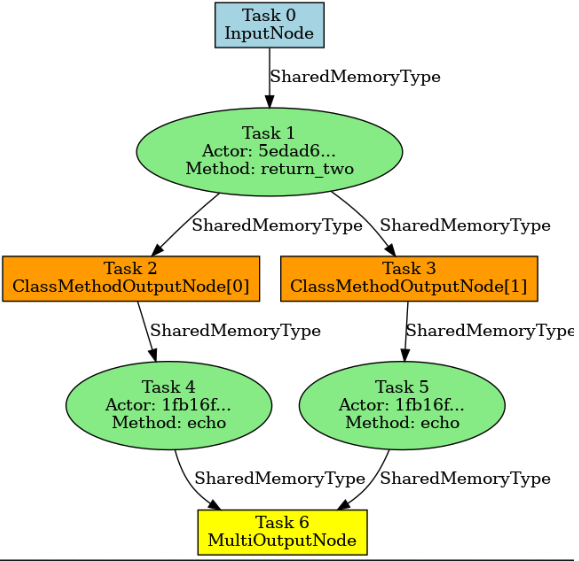
import ray import time import random from ray.dag.input_node import InputNode from ray.dag.output_node import MultiOutputNode ray.init(address = "10.218.163.33:6274") import os @ray.remote classActor: def__init__(self, init_value, fail_after=None, sys_exit=False): self.i = init_value self.fail_after = fail_after self.sys_exit = sys_exit
self.count = 0
defecho(self, x): self.count += 1 return x
defsleep(self, x): time.sleep(x) return x
@ray.method(num_returns=2) defreturn_two(self, x): return x, x + 1
defread_input(self, x): return x
a = Actor.remote(0) b = Actor.remote(0) single_fetch = True with InputNode() as i: o1, o2 = a.return_two.bind(i) o3 = b.echo.bind(o1) o4 = b.echo.bind(o2) dag = MultiOutputNode([o3, o4])
compiled_dag = dag.experimental_compile() for _ inrange(3): refs = compiled_dag.execute(1) if single_fetch: for i, ref inenumerate(refs): res = ray.get(ref) assert res == i + 1 else: res = ray.get(refs) assert res == [1, 2] compiled_dag.visualize() compiled_dag.teardown()
def_execute_impl(self, *args, **kwargs): """Executor of FunctionNode by ray.remote(). Args and kwargs are to match base class signature, but not in the implementation. All args and kwargs should be resolved and replaced with value in bound_args and bound_kwargs via bottom-up recursion when current node is executed. """ return ( ray.remote(self._body) .options(**self._bound_options) .remote(*self._bound_args, **self._bound_kwargs) )
classClassNode: def__getattr__(self, method_name: str): # User trying to call .bind() without a bind class method if method_name == "bind"and"bind"notindir(self._body): raise AttributeError(f".bind() cannot be used again on {type(self)} ") # Raise an error if the method is invalid. getattr(self._body, method_name) call_node = _UnboundClassMethodNode(self, method_name, {}) return call_node
def_execute_impl(self, *args, **kwargs): """Executor of ClassMethodNode by ray.remote() Args and kwargs are to match base class signature, but not in the implementation. All args and kwargs should be resolved and replaced with value in bound_args and bound_kwargs via bottom-up recursion when current node is executed. """ if self.is_class_method_call: method_body = getattr(self._parent_class_node, self._method_name) # Execute with bound args. return method_body.options(**self._bound_options).remote( *self._bound_args, **self._bound_kwargs, ) else: assert self._class_method_output isnotNone return self._bound_args[0][self._class_method_output.output_idx]
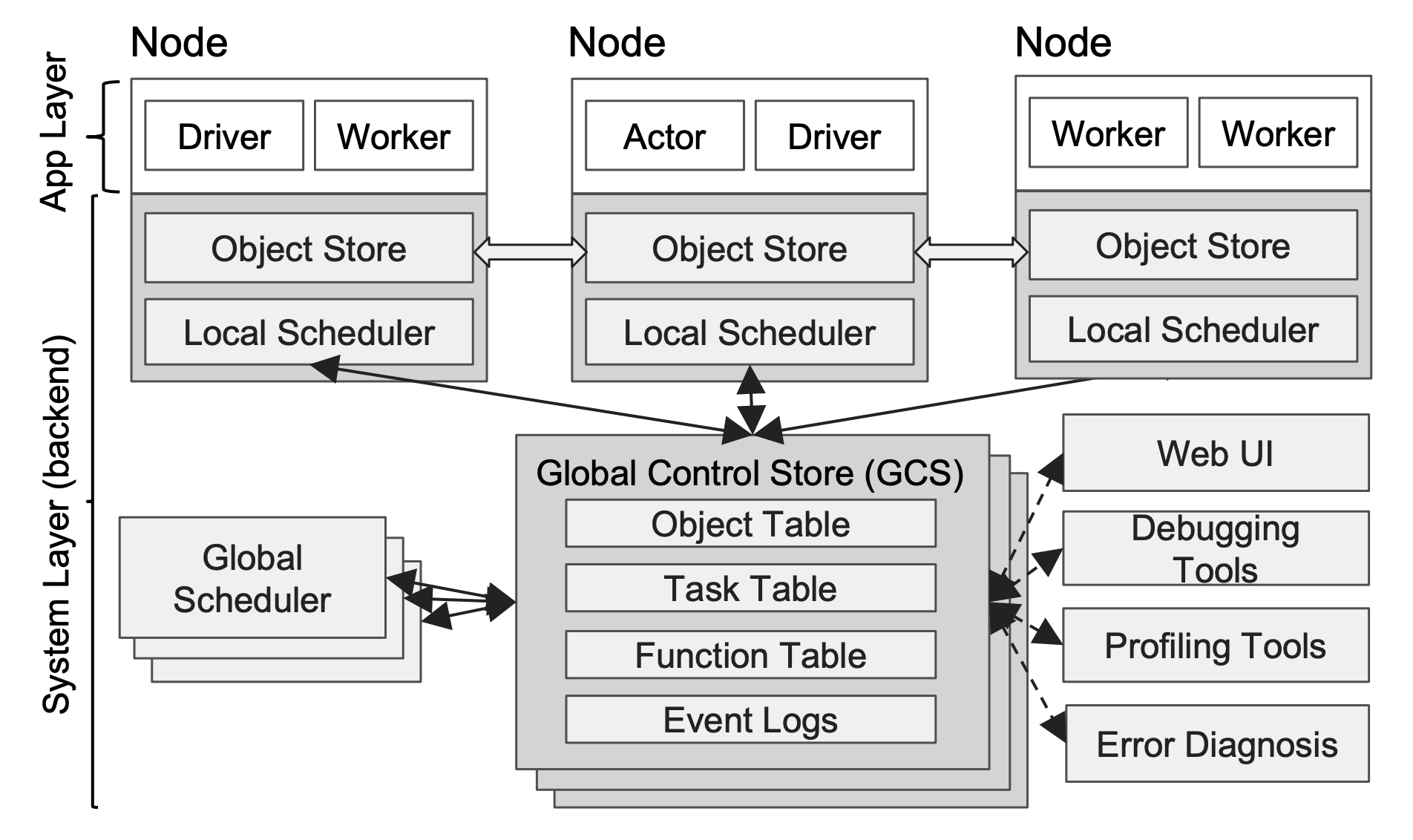
Ray 的 GCS Server 是 Ray
框架的核心组件,负责元数据存储、任务调度、资源管理和集群状态维护。它通过存储模块(Redis
或 内存)管理节点和任务的生命周期,使用 Pub-Sub
系统进行状态广播,并通过高效的调度协调与其他组件(如 Scheduler, Worker,
Actor 或
Object)协作,确保系统的高性能、高可用性和灵活扩展性。gcs_server是一个非Python进程,二进制文件路径在
ray/python/ray/core/src/ray/gcs/gcs_server。
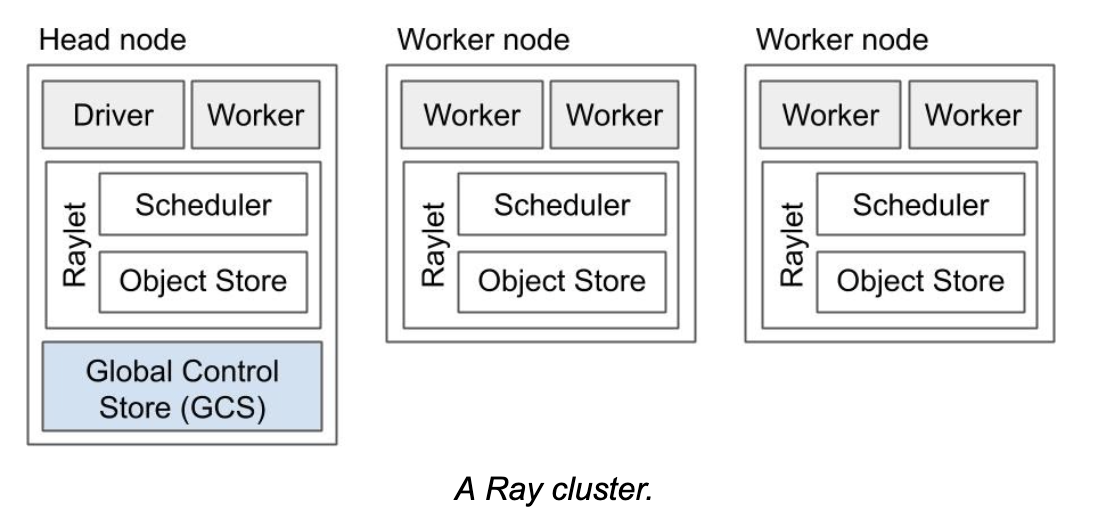
raylet
Raylet 是 Ray
集群中每个节点的核心运行时组件,负责任务执行、资源管理和数据依赖协调。它接收
GCS Server 分配的任务,管理本地资源,启动 Worker 进程执行任务,并通过
Plasma Store 处理数据存储与传输。同时,Raylet 定期向 GCS Server
汇报节点状态,协作实现任务调度、资源分配和故障恢复,是 Ray
分布式运行的关键执行单元。raylet是一个非Python进程,二进制文件路径在
ray/python/ray/core/src/ray/raylet/raylet。
worker
Worker 是 Ray 中的核心计算单元,由 Raylet 启动,负责具体任务的执行和
Actor 的运行。它与 Plasma Store 协作进行数据存取,并通过与 Raylet
的通信完成任务调度和资源管理。Worker 支持多语言运行环境(如
Python、Java),能够高效并行处理任务,是 Ray
框架实现分布式计算的基础组件。
actor
Actor 是 Ray
框架中的一种状态管理单元,允许用户在分布式系统中创建带有持久状态的计算对象。每个
Actor 由一个独立的 Worker
进程运行,支持并行调用方法并维护自身状态。Actor
可以通过远程调用接口与其他组件交互,实现任务分解和动态扩展,是 Ray
中用于构建有状态应用和分布式服务的重要抽象。
RAY_INSTALL_JAVA: If set and equal to 1,
extra build steps will be executed to build java portions of the
codebase
RAY_INSTALL_CPP: If set and equal to 1,
ray-cpp will be installed
RAY_DISABLE_EXTRA_CPP: If set and equal to
1, a regular (non - cpp) build will not
provide some cpp interfaces
SKIP_BAZEL_BUILD: If set and equal to 1,
no Bazel build steps will be executed
SKIP_THIRDPARTY_INSTALL: If set will skip installation
of third-party python packages
RAY_DEBUG_BUILD: Can be set to debug,
asan, or tsan. Any other value will be
ignored
BAZEL_ARGS: If set, pass a space-separated set of
arguments to Bazel. This can be useful for restricting resource usage
during builds, for example. See https://bazel.build/docs/user-manual for
more information about valid arguments.
IS_AUTOMATED_BUILD: Used in CI to tweak the build for
the CI machines
SRC_DIR: Can be set to the root of the source checkout,
defaults to None which is cwd()
BAZEL_SH: used on Windows to find a
bash.exe, see below
BAZEL_PATH: used on Windows to find
bazel.exe, see below
MINGW_DIR: used on Windows to find
bazel.exe if not found in BAZEL_PATH
ray start --head ##Local node IP: 192.168.64.8 ## ##-------------------- ##Ray runtime started. ##-------------------- ## ##Next steps ## To add another node to this Ray cluster, run ## ray start --address='192.168.64.8:6379' ## ## To connect to this Ray cluster: ## import ray ## ray.init() ## ## To submit a Ray job using the Ray Jobs CLI: ## RAY_ADDRESS='http://127.0.0.1:8265' ray job submit --working-dir . -- python my_script.py ## ## See https://docs.ray.io/en/latest/cluster/running-applications/job-submission/index.html ## for more information on submitting Ray jobs to the Ray cluster. ## ## To terminate the Ray runtime, run ## ray stop ## ## To view the status of the cluster, use ## ray status ## ## To monitor and debug Ray, view the dashboard at ## 127.0.0.1:8265 ## ## If connection to the dashboard fails, check your firewall settings and network configuration.
可以在http://127.0.0.1:8265查看Ray控制台。
启动Node节点
1 2 3 4 5 6 7 8 9 10 11
ray start --address='192.168.64.8:6379' ##Local node IP: 192.168.64.9 ##[2025-01-21 10:49:34,903 W 1882 1882] global_state_accessor.cc:463: Retrying to get node with node ID ba8aafea9f23f6f29ff6cd174e31aaac37cddb0e832c4e3170ddcf63 ## ##-------------------- ##Ray runtime started. ##-------------------- ## ##To terminate the Ray runtime, run ## ray stop
RAY_GRAFANA_HOST=http://192.168.64.8:3000 ray start --head --dashboard-host=0.0.0.0
RAY_GRAFANA_HOST的作用是让ray的dashboard能够访问到grafana服务;
--dashboard-host=0.0.0.0允许所有ip访问。
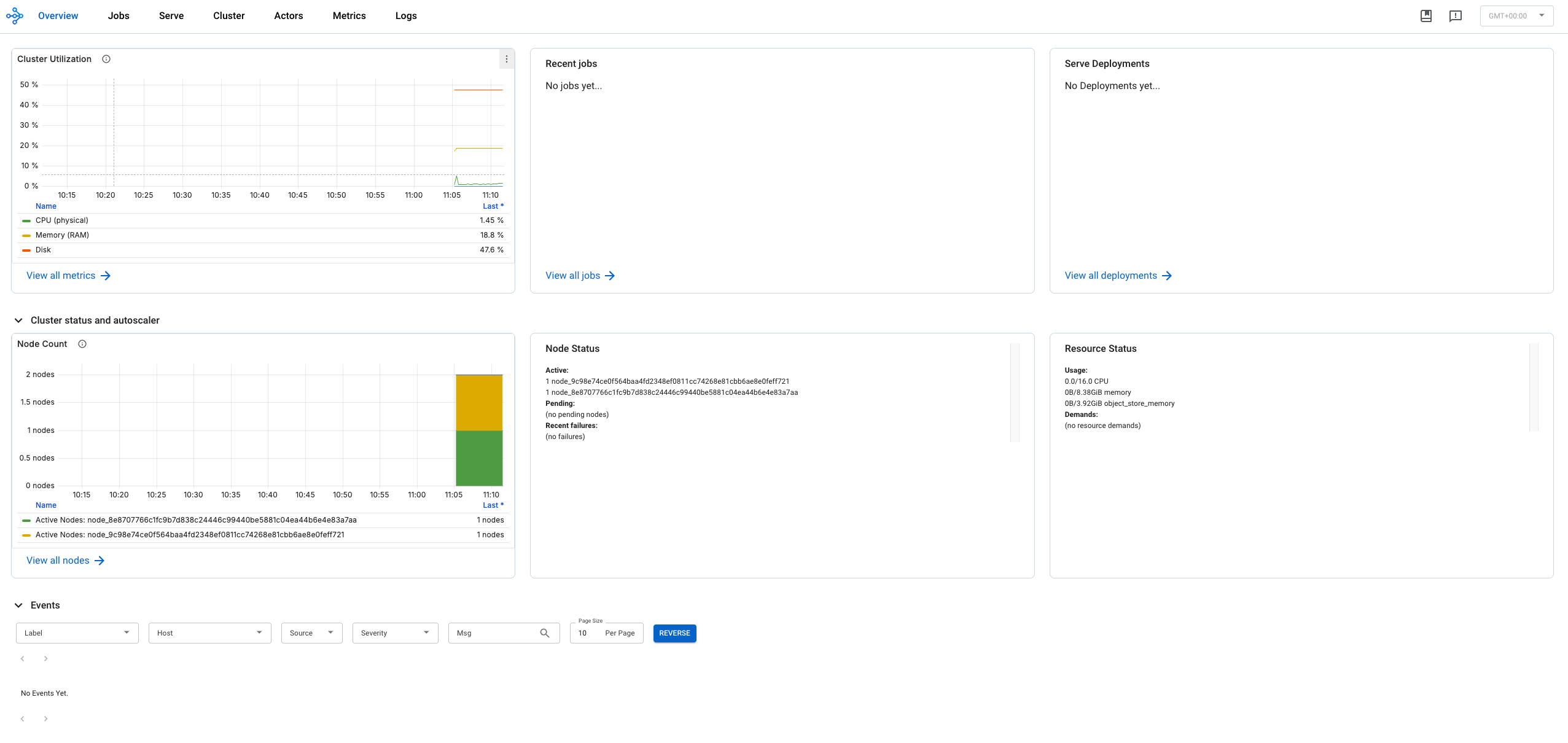
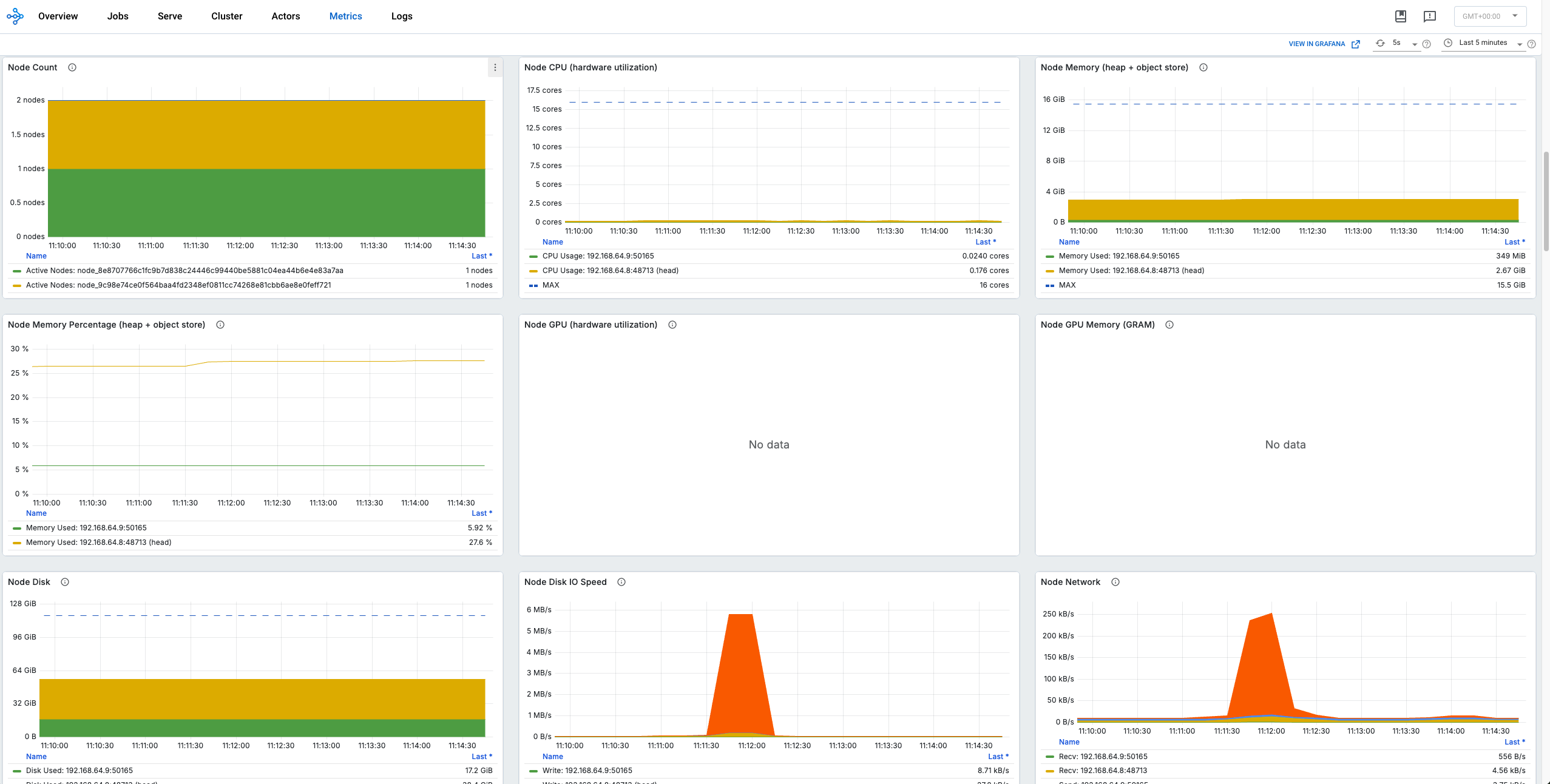
Ray dashboardRay dashboard
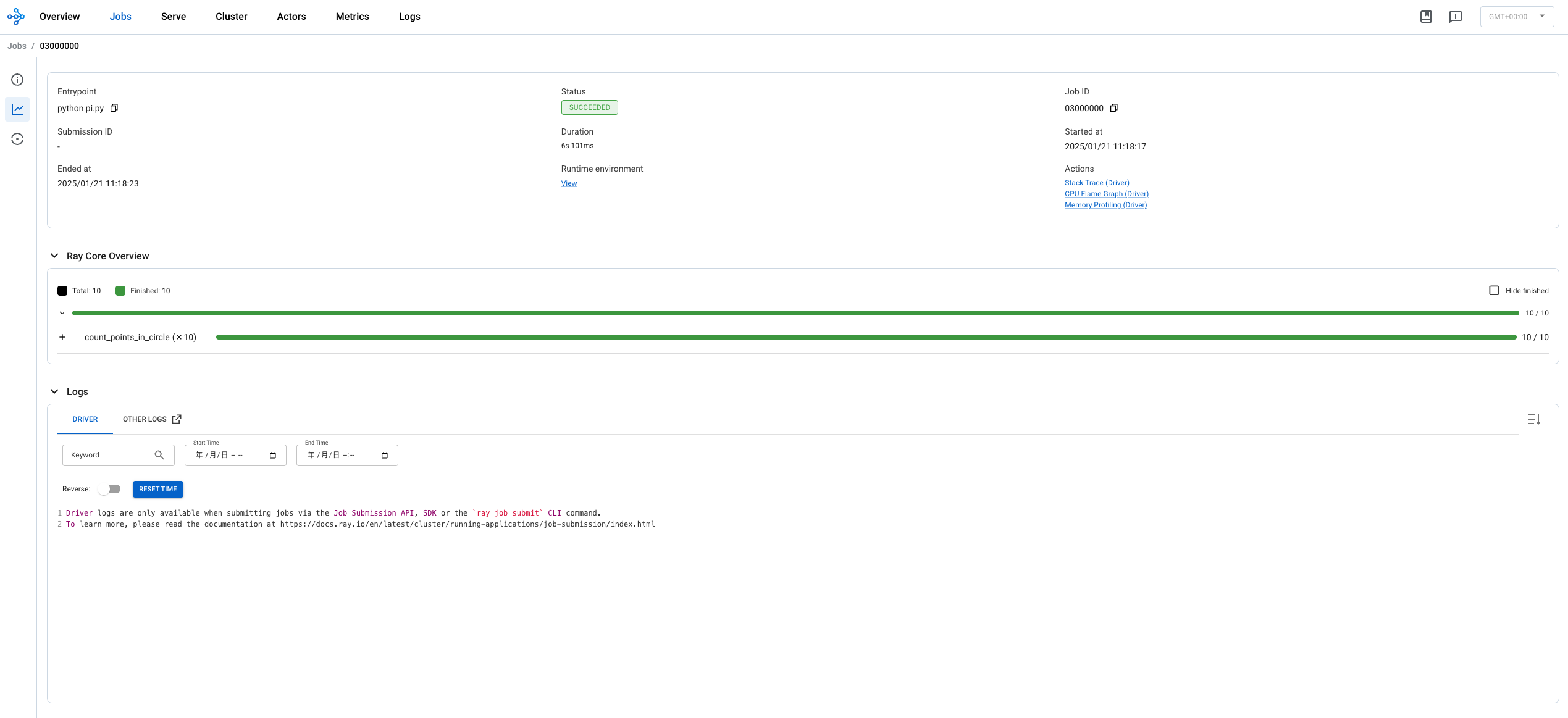
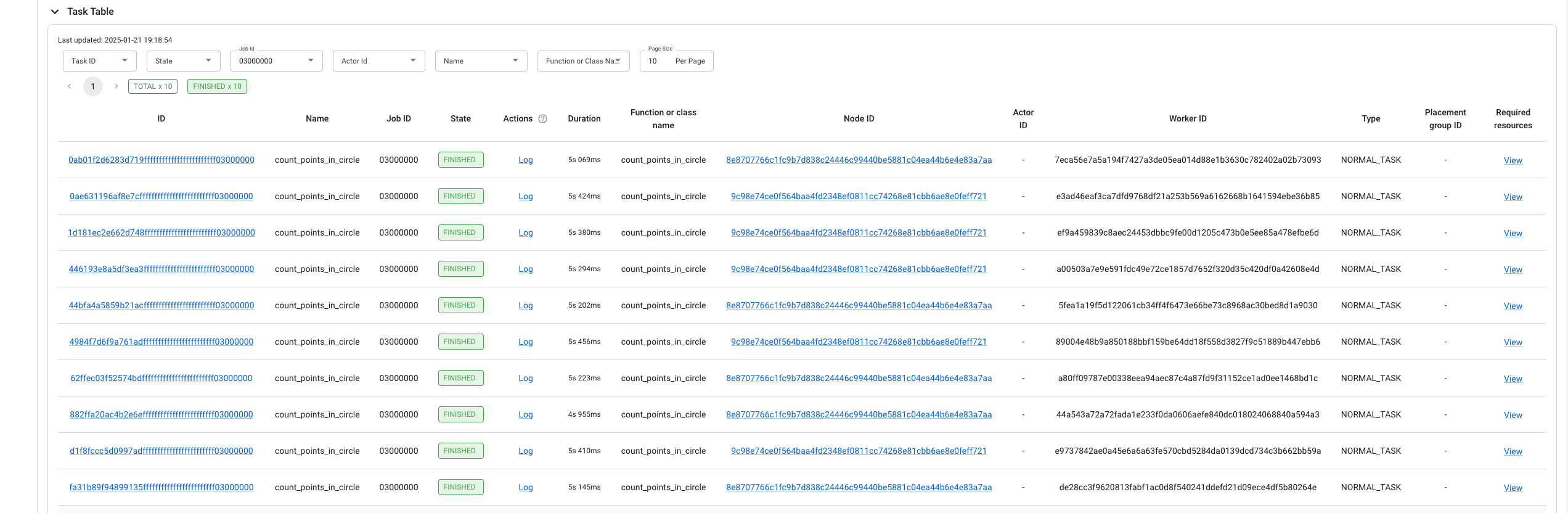
提交一个任务
1 2 3 4 5
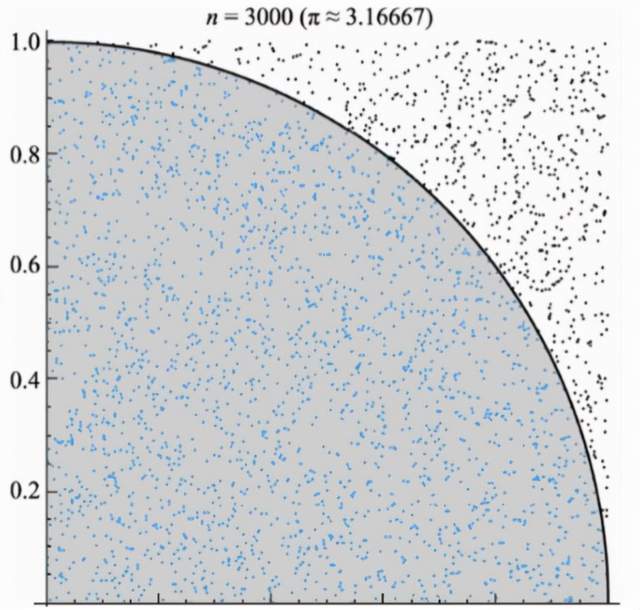
python pi.py ##2025-01-21 11:17:11,760 INFO worker.py:1654 -- Connecting to existing Ray cluster at address: 192.168.64.8:6379... ##2025-01-21 11:17:11,775 INFO worker.py:1832 -- Connected to Ray cluster. View the dashboard at 192.168.64.8:8265 ##Estimated π: 3.36
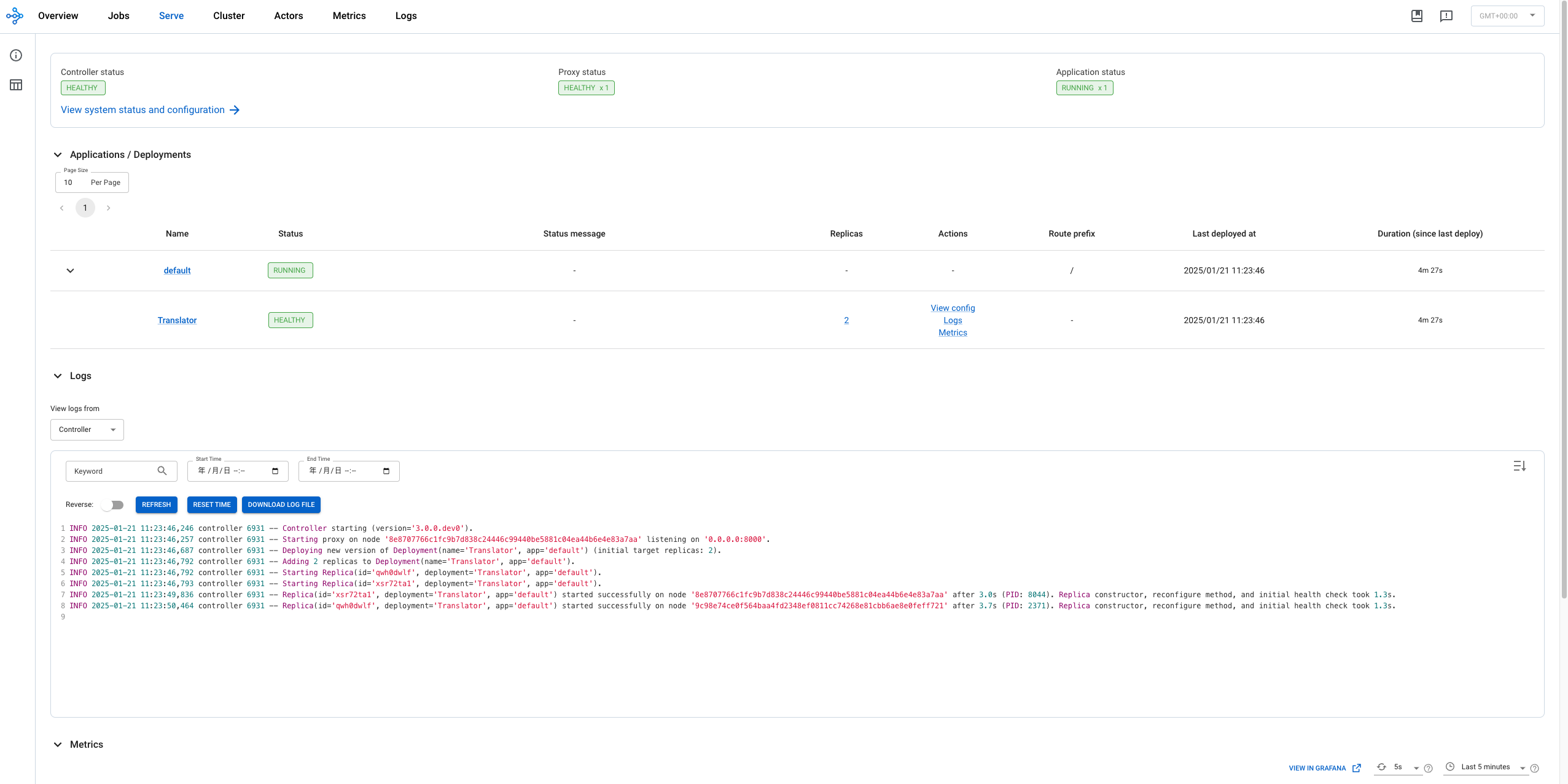
python translate.py ##2025-01-21 11:23:45,794 INFO worker.py:1654 -- Connecting to existing Ray cluster at address: 192.168.64.8:6379... ##2025-01-21 11:23:45,810 INFO worker.py:1832 -- Connected to Ray cluster. View the dashboard at 192.168.64.8:8265 ##INFO 2025-01-21 11:23:46,673 serve 8302 -- Started Serve in namespace "serve". ##INFO 2025-01-21 11:23:46,675 serve 8302 -- Connecting to existing Serve app in namespace "serve". New http options will not be applied. ##WARNING 2025-01-21 11:23:46,675 serve 8302 -- The new client HTTP config differs from the existing one in the following fields: ['host', 'location']. The new HTTP config is ignored. ##(ServeController pid=6931) INFO 2025-01-21 11:23:46,687 controller 6931 -- Deploying new version of Deployment(name='Translator', app='default') (initial target replicas: 2). ##(ProxyActor pid=8045) INFO 2025-01-21 11:23:46,644 proxy 192.168.64.8 -- Proxy starting on node 8e8707766c1fc9b7d838c24446c99440be5881c04ea44b6e4e83a7aa (HTTP port: 8000). ##(ProxyActor pid=8045) INFO 2025-01-21 11:23:46,660 proxy 192.168.64.8 -- Got updated endpoints: {}. ##(ProxyActor pid=8045) INFO 2025-01-21 11:23:46,690 proxy 192.168.64.8 -- Got updated endpoints: {Deployment(name='Translator', app='default'): EndpointInfo(route='/', app_is_cross_language=False)}. ##(ServeController pid=6931) INFO 2025-01-21 11:23:46,792 controller 6931 -- Adding 2 replicas to Deployment(name='Translator', app='default'). ##(ServeReplica:default:Translator pid=8044) Device set to use cpu ##INFO 2025-01-21 11:23:50,711 serve 8302 -- Application 'default' is ready at http://0.0.0.0:8000/. ##INFO 2025-01-21 11:23:50,711 serve 8302 -- Deployed app 'default' successfully. ##(ServeReplica:default:Translator pid=2371, ip=192.168.64.9) Device set to use cpu
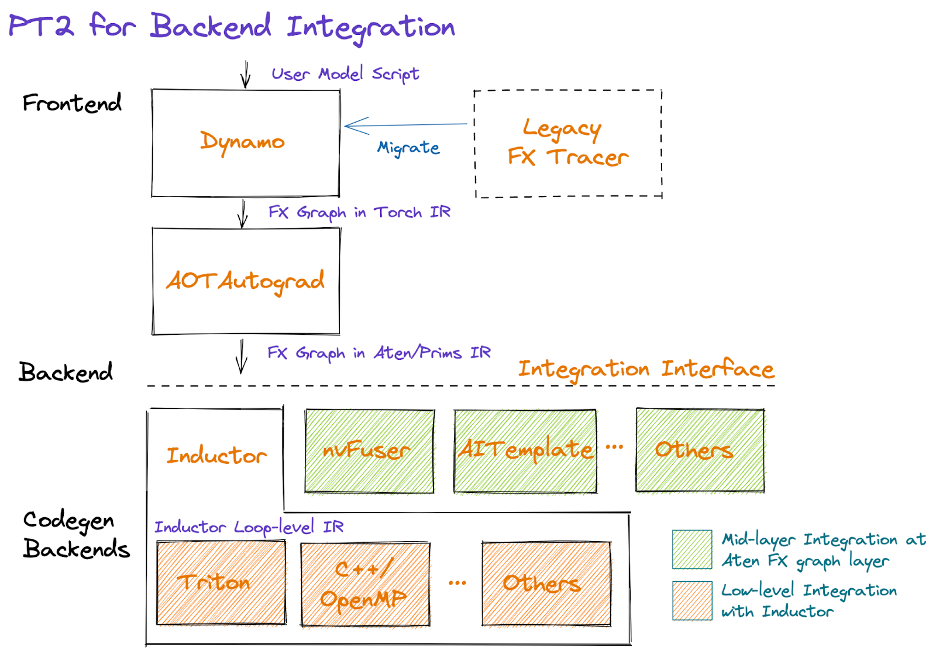
PyTorch有多个后端编译器,都可以从FX
Graph进行模型编译。Intree的有cudagraph,onnxrt,openxla,tvm以及inductor,out
of
tree的有nvFuser和AITemplate等。Inductor相较于其他编译器,有以下优势,并逐渐成为PyTorch主力发展的编译器。
动态编译:能够根据输入数据的特性在运行时生成优化代码,实现最佳性能。
实时优化:允许在推理过程中对计算图进行修改和优化,无需重新编译整个模型。
支持复杂操作:处理多种复杂操作和动态控制流,增强模型的表达能力。
集成现有 API:与 PyTorch API
无缝集成,降低学习曲线,方便开发者使用。
硬件适配:根据不同硬件生成特定优化代码,充分利用计算能力,目前支持CPU和GPU。
配置选项:提供多种参数和选项,允许用户自定义优化策略,增强灵活性。
性能调优:在运行时监控性能,根据实际情况自动选择最优执行路径。
Inductor会做很多通用优化,使得使用Inductor
IR的后端均可以享受到这些优化的能力。
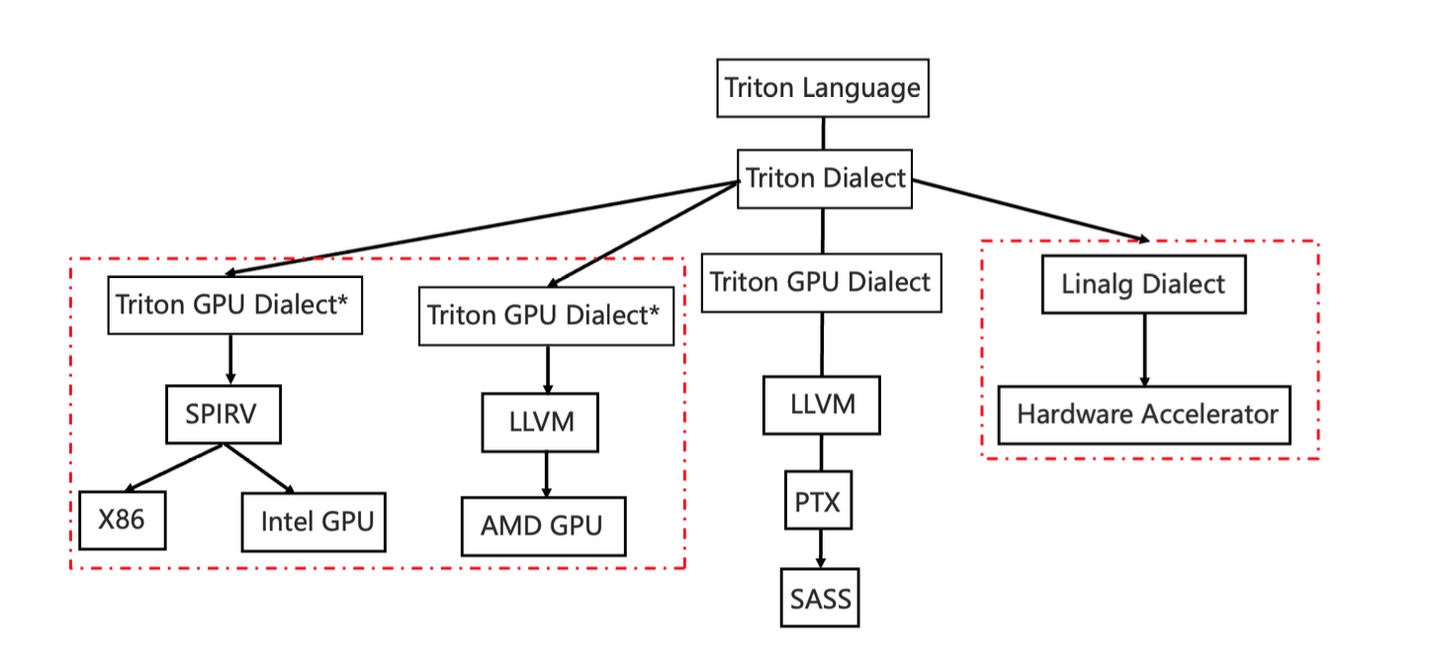
Integrating a new backend at the AtenIR/PrimsIR level is
straightforward and provides more freedom to the new backend to optimize
the captured graph. But it might be suboptimal performance if the
backend lacks the DL compiler capability because the decomposed
operations for a single operation might need more memory and worse data
locality compared with the single operation if the decomposed operations
can't be fused.
Integrating at the Inductor loop IR level can significantly simplify
the complexity of design and implementation by leveraging the Inductor's
fusion capability and other optimizations directly. The new backend just
needs to focus on how to generate optimal code for a particular
device.
git clone --recursive https://github.com/pytorch/pytorch cd pytorch # if you are updating an existing checkout git submodule sync git submodule update --init --recursive
conda install cmake ninja # Run this command from the PyTorch directory after cloning the source code using the “Get the PyTorch Source“ section below pip install -r requirements.txt